

Dalija Prasnikar
-
Content Count
1060 -
Joined
-
Last visited
-
Days Won
91
Posts posted by Dalija Prasnikar
-
-
15 hours ago, Attila Kovacs said:I came across this ineresting post https://stackoverflow.com/questions/27368556/trtticontext-multi-thread-issue after getting an error report over an AV in System.Rtti.MakeClosure
and I'm wondering, according to the answers from @Stefan Glienke and @David Heffernan if the "data := nil;" in System.Rtti.LazyLoadAttributes,MakeClosure should not be the first after
the second check?
First of all, when asking about particular issue specifying Delphi version is mandatory. System.Rtti is being updated for literally every release (including updates). If you want us to comment on source code we need to make sure that we are looking at the same code.
The code in question is perfectly fine. But the whole thing is broken in another place. Namely procedure TRttiInstanceType.ReadPropData; and other similar methods which use boolean for checking, but without double checked locking. This can causes calling LazyLoadAttributes twice which then can corupt the whole thing in that code. For instance I would get a crash on nil Finalizer instance.
if FReadPropData then Exit; p := PByte(TypeData.PropData); TMonitor.Enter(Package.FLock); try // Here we would need to check FReadPropData again end exit if it is true classic := ReadClassicProps; ext := ReadExtendedProps; FProps := SubtractClassic(classic, ext); FAttributeGetter := LazyLoadAttributes(p); FIndexedProps := ReadIndexedProps; FReadPropData := True; finally TMonitor.Exit(Package.FLock); end; end;-
 1
1
-
-
17 minutes ago, Kas Ob. said:It handle a translated version without colors, while browsers handle this more elegantly and translate it back to the 4 bytes version
This is not encoding, this is visual representation. Underlying encoding (numbers) is the same.
-
52 minutes ago, Kas Ob. said:Anyway, i sounded my opinion about such GDI leak from AlphaSkin based on my point of view, and still see the cause by overflowing buffers or overwriting memory, to me the logical and easiest way to explain such behavior based on what OP said all happen with introducing ICS with OpenSSL and threading, and the fact if this overflowing was having anything else than zero's AlphaSkin code should generated hell of exceptions, threading problem can't be so consistent with zeroing memory, this leads me to deduct the only place that could make this happen with Delphi 7 and it outdated way to handle strings with different encoding coming from OpenSSL input and output, that is it.
There is still a lot of code running in that thread that we haven't seen and don't know how it interacts with other code and might cause memory corruption for various reasons. But the string encoding/decoding code we have seen is not it, no matter how outdated or not.
-
37 minutes ago, Kas Ob. said:This is not a problem as long the input from Delphi or from a system like Windows OS which traditionally couldn't and didn't in the past support these UCS-4 aka UTF32, but now windows does support them like Android, and this makes a problem.
Take an example this pizza slice emoji 🍕, in the past there wasn't away to input from keyboard but now windows does support it, this pizza slice is 3 bytes in Unicode, but it is 4 bytes in UTF8 and UTF16, and Delphi with its String or WideString will not be able to handle it, but again since long time ago
Delphi can perfectly handle pizza slice emoji with either UTF8String or WideString. How do you think it was handling Chinese characters that were spanning two UTF-16 code units?
Unicode encoding is a standard no matter what OS you are using. The most that can happen is that you cannot properly display the character because you are lacking appropriate font.
Now I cannot claim that Delphi 7 encoding/decoding functions are capable of handling all those correctly as I haven't tried, but even in Delphi 7 those functions could be replaced with the ones that handle them properly.
-
16 hours ago, Kas Ob. said:17 hours ago, Dalija Prasnikar said:If Unicode character would require 4 bytes in UTF8 encoding, then it would also require two wide characters (UTF16 encoding) which means reserved number of bytes for such character would be 2 * 3 = 6.
True, but, UTF16 is either one or 2 of 16bit units ( it is called unit in Wikipedia), so it is either 2 bytes or 4 bytes, why this wasn't ever a problem with all versions of Delphi ?,
What problem?
In context of wide string we can talk about wide characters where each such character stores one 16-bit code unit. This is important for determining the length of the wide string which is measured in number of wide characters - 16-bit code units.
So full Unicode character can be stored either in single or two 16-bit wide characters, which means that for characters that span two wide characters reserved space will be 2 * 3 which is more than enough to store that whole Unicode character in UTF8 representation which can be maximum 4 bytes. There is no Unicode character that fully fits into single 16-bit code unit that requires more than 3 bytes when encoded in UTF8.
16 hours ago, Kas Ob. said:The is : simply because all the input and output where either internally generated data or by the OS ( mostly Windows), Windows API always refer to them as Wide, anyway this shouldn't a problem as long as the input and output is from Delphi application or the Windows, but in this very case the data are coming from remote place over the wire who knows the origin, also being handled by OpenSSL, so assuming it is will be 2 bytes UTF8 or even 2 bytes UTF16 is at least doubtful.
I have no idea what you want to say here.
16 hours ago, Kas Ob. said:17 hours ago, Dalija Prasnikar said:Also if the supplied buffer is not enough then the called conversion function would fail (without causing buffer overrun) and would return 0 and such scenario is fully covered by UTF8Encode function.
I really looked and looked then looked again, i just don't see failing point in both functions Utf8Encode and UnicodeToUtf8, this UnicodeToUtf8 though does trim but never fail, will return 0 if the input is an empty string other than that it will trim the result according to supplied buffer if it is shorter than needed, but will not fail.
I was in a hurry and I took wrong turn while looking at code. Yes, you are right, the conversion function does not fail. The main point still stands and it does not cause buffer overrun. And again coming from UTF8Encode, conversion buffer allocates enough space for successful conversion of WideString content.
So the bug in the code we are discussing here does not come from handling strings and their buffers, at least not in the code that was presented here.
-
1 hour ago, Kas Ob. said:How is this not wrong if this function assumes a UTF8 char can be only 3 bytes max instead of 4 ?
What else is wrong with that conversion function, have you seen these two calls in one line of code, are we juggling strings left and right through many types from WideString, AnsiString then UTF8String with wrong max length and expect it to not be wrong, because it does work sometimes ?
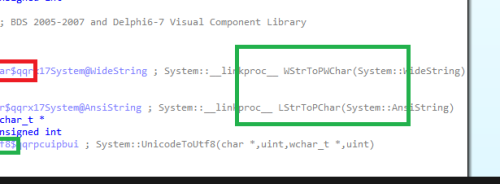
The function is not wrong. If Unicode character would require 4 bytes in UTF8 encoding, then it would also require two wide characters (UTF16 encoding) which means reserved number of bytes for such character would be 2 * 3 = 6. Also if the supplied buffer is not enough then the called conversion function would fail (without causing buffer overrun) and would return 0 and such scenario is fully covered by UTF8Encode function.
-
1 hour ago, TazKy said:A sinister thought could be that one day Google could force every app being considered for its play store be exclusively built using Android Studio only due to its every restricting security requirements with each version release.
That would not happen since they support C++ in Android Studio. And such compiled code is no different than Delphi code.
-
1
-
-
45 minutes ago, Kas Ob. said:Also was there a UTF8String in Delphi 7 ? and how it being handled in , what did Length() return, length in bytes or in chars ?
Yes, there is a UTF8String in Delphi 7.
7 minutes ago, uso said:Off-topic: UTF-8 is 1 to 4 byte(s) per char depending on the respective code point.
That is not what character means. It is how much code units are required for encoding Unicode code point in specific encoding.
Unicode character is called a code point and depending on encoding each code point can occupy from 1 to 4 bytes https://stackoverflow.com/questions/2241348/what-are-unicode-utf-8-and-utf-16
Character in Delphi can have different meanings:
One is
Chartype which can have size of one or two bytes depending on Delphi version (pre 2009 or 2009+). There are also other character types which can have different byte sizes.Another one is used in terms of character type used in various string types: character size for AnsiString and UTF8String in all Delphi versions is one byte, for default string type in pre Unicode versions size of character is one byte, for Unicode versions size is two bytes.
Length function always returns the size in characters for particular string type which means the actual number of bytes will depend on the character size for that string type. for UTF8String length will always equal the number of bytes because size of character in UTF8String is one byte, regardless whether some Unicode characters (code points) require more that one byte when encoded.
19 minutes ago, uso said:It is not a trival task to get the exact byte size of an UTF-8 coded string.
Yes it is. Just call the Length function on it.
20 minutes ago, uso said:You need to put into consideration every code point. If you know your input languages, you may be able to approximate it - most of the time..
You only need to consider how many bytes are in codepoint if you are parsing such data byte by byte, where accessing UTF8String by index will not necessarily give you complete information about Unicode code point stored as you will get only one byte of it.
-
 1
1
-
-
10 minutes ago, Kas Ob. said:Here if UTF8 is 2 bytes per char then it should be
UTF8String is always one byte per char, regardless of a Delphi version.
-
1
-
-
14 minutes ago, Angus Robertson said:ICS components could set the MultiThreaded property automatically, but the developer would still need to call IcsWndControl.ProcessMessages somewhere in the thread or the code would just stall, except in the simplest of applications.
Yes, you are right. I am trying to solve one problem, while forgetting the broader picture. Although it might be easier to figure out what is wrong if the thread would just stall, comparing to having random issues somewhere else in the application.
-
1
-
-
11 minutes ago, PizzaProgram said:But it depends, how much time (CPU cycles) would it take to get the Current Thread's ID.
Those few cycles mean nothing comparing to constructing the whole component over and over again. So this kind of safeguard can be easily implemented without having any negative side effects. The property itself could be left as-is, but initial value can be set in constructor depending on the thread ID value:
FMultiThreaded := TThread.CurrentThread.ThreadID <> MainThreadID;-
1
-
-
22 minutes ago, Angus Robertson said:the code is said to be running in a thread, but the MultiThreaded property of TSslHttpCli is never set, so messages for the thread will be processed using Application.ProcessMessages in a different thread.
Well, that is rather unfortunate design choice as it can be easy for users of a library to overlook this requirement.
Wouldn't it be better to autodetect whether component is created within background thread and set that property automatically rather than manually?
-
You can find more information in this thread
-
You need to recompile your application with the latest Delphi 11.3 and submit that to Play Store See: https://docwiki.embarcadero.com/RADStudio/Alexandria/en/Supported_Target_Platforms#cite_note-11.3-1
-
4 hours ago, PizzaProgram said:And it only happens, if the ICS background thread is RUNNING. Never if it's stopped, or not started at all.
While if I check the GDI object number with a separate program, it is always less than 1000! (The default max is 10.000 in windows.)
If the issue happens only when background thread is running, then background thread creates a problem.
4 hours ago, PizzaProgram said:GDI < 900
Handles < 400
So logically in every 2-4 hours it can reach 32bit limit. (2GB)
This sounds like memory issue, if FASTMM is not registering the leak, you are probably allocating and holding on to some memory that accumulates inside the thread. Another potential issue without a visible leak could be a memory fragmentation and then you have an issue when you try to allocate larger block of memory like bitmap.
-
4 hours ago, PizzaProgram said:But if that would be true, than a simple "process explorer" would show memory consumption of > 2GB, and not just 150MB. Am I wrong?
Yes. I started with explanation how to approach memory allocation issues (since you mentioned FASTMM), but I should have been more clear that this part is most likely not related to your current issue.
-
52 minutes ago, PizzaProgram said:Can you please explain, what do you mean by that?
The background thread does not interact with the GUI at all! None of my thread do ever.
(Except if ICS is doing it somehow without my knowledge?)
It means that either code in the GUI or the code in thread is exhausting the memory. So you need to know which one causes the problem if you want to locate it.
For start, just comment out all the code in thread and see how application behaves, then you can start turning on parts of the code in thread until you hit the issue. There is plenty of code we don't see here so it is hard to say what is the problem.
Just because FASTMM does not show the leak that does not mean that there is no memory leak, it is just that it is not classical memory leak where you allocate memory and you don't release it. Another form of a leak is that you keep allocating memory and holding on to it even after you no longer need it. such memory will be properly released on application exit, but while running application can still exhaust all available memory.
BTW, some of your code in thread is not properly handling allocations/deallocations.
You have try...finally blocks that do more than they should, you don't protect all allocations with try block - the other option, would be to initialize all object instances to nil first, and you have unnecessary Assigned checks before calling Free which can safely run on nil object instances. All that tells me that your memory management code is not exactly stellar and that you probably similarly poor code in other parts of your application. So chances are rather high that your code somewhere in your application is causing you a trouble and that it has nothing to do with ICS alone.
However, EOutOfResources error is not about a memory allocation but leaking GDI objects. Those leaks will not be reported by FASTMM. Because it is wrapped inside GDICheck it is possible that there is no leak at all, but some other GDI error.
-
30 minutes ago, Attila Kovacs said:33 minutes ago, aehimself said:or a similar (automatic) content checking
chatGPT
I would like to see that one working... https://meta.stackexchange.com/a/391067/313443
-
3 minutes ago, Sherlock said:Please be vigilant guys, and we'll try to react and delete as fast as possible
Stack Overflow has a good system with casting flags where certain amount of flags automatically deletes the post. Flags are available based on reputation to prevent abuse and bad flags cause flagging suspension. Also moderators can issue manual suspension.
Because we are small forum, you could even manually give such delete flag capabilities to trusted users where you know they will not be abused and automatically delete posts even with single flag. There is enough of us to keep the site clean, the only thing needed is infrastructure that would allow that.
-
3
-
-
23 hours ago, Roger Cigol said:I certainly agree with @Dalija Prasnikar there is nothing worse than a compiler warning that is wrong. It is hard to make them "go away" and they definitely can "hide" other useful warnings.
I will have to change my position. I was focused on behavior where compiler would catch all cases where record would be uninitialized - by all I don't mean having different code paths where compiler cannot easily determine whether something is initialized or not even for types it currently shows warnings.
To catch all such cases, calling record method would also need to show a warning, but there is no way compiler can differentiate between method that initializes a record and method that expects already initialized method - the difference between imagined TGuid.Clear and TGUID.IsEmpty.
However, for other value types calling a method does not trigger a warning and simply disables further warnings, so such behavior could be easily extended to non-managed fields in records without causing any bogus warnings and would not be any more difficult to achieve than existing warnings for other value types.
It is likely that variant parts in records would have to be excluded as accessing and initializing one field does not mean that another field that shares same memory would be fully initialized (memory overlap can be only partial) and it is possible that tracking sizes and what is initialized and what not would be too much in such scenario.
There is a value in showing at least some warnings comparing to none.
-
1
-
-
13 minutes ago, Attila Kovacs said:I understand but I think those excuses are made up.
I think there was some article about C# covering similar area that explained the problems rather well. I cannot find it now.
-
1 hour ago, Attila Kovacs said:Does this 'more complex' mean that we don't care, or that we sweated hard and got it done? 🙂
It means that it can be hard to tell whether record is initialized or not. For instance you could have TGuid.Clear method that would initialize record, but there is not way to tell what that method does comparing to TGuid.IsEmpty or any other that would expect initialized record.
It is not as much that warnings cannot be emitted, but that there would be a lot of bogus warnings in such case, which defeats the purpose of a warning.
-
1
-
-
26 minutes ago, Attila Kovacs said:Ahm, isn't there a compiler hint missing then?
From https://quality.embarcadero.com/browse/RSP-24383 Warning/Error on record fields used without initialization
QuoteSync status from internal system, internal issue closed on Feb 11, 2023 by Marco Cantù with comment:
Because records can be initialized and allocated in different ways, this ir much more complex than a local var. Also methods have optional initialization now.-
1
-
-
TGUID is a regular record type, so it is not initialized. Only managed types are initialized, including custom managed records.
Double checked locking
in RTL and Delphi Object Pascal
Posted
I reported the issue as https://quality.embarcadero.com/browse/RSP-42359