

jeroenp
-
Content Count
29 -
Joined
-
Last visited
-
Days Won
1
Posts posted by jeroenp
-
-
1 hour ago, David Schwartz said:Ok, thanks for all of this juicy info. I've learned a bit, but I'm still not sure what to tell someone who sends emails or posts things that have words with apostrophes in them that look like: I’m can’t won’t and so on.
Point them to the Problems in different writing systems section of the Wikipedia Mojibake page.
1 hour ago, David Schwartz said:I've solved my problem, but that’s not it. 🙂
Did you really solve them of worked around with the table-based approach? Because if you did that, you are bound to be incomplete.
1 hour ago, David Schwartz said:I've also found that if you load things that look like this
<break time='5s' />
into TMS WEB Core visual controls, they get eaten up because the browser apparently thinks they're XML tags or something like that. So I changed them to this
That's a thing many web-tools do. You should reproduce this and report it as an issue to the TMS WEB Core bug category.
The classic WordPress editor suffers from the same issue (and a whole lot more issues: search my blog for more), but they marked it as "legacy" while forcing the very a11y* unfriendly (and pretentiously named) Gutenberg editor (which has other issues, but I digress) into peoples face.
1 hour ago, David Schwartz said:«break time='5s' /»
which works great. And, yes, I tried < / > but they got automatically converted and THEN the whole "tag" got eaten up.
The WordPress classic editor, trying to be smart, does that too especially when you switch between preview and HTML text modes a few times. The TMS WEB Core might fall in a similar trap. Be sure to report it as bug to the TMS people.
--jeroen
* a11y: accessibility-
 1
1
-
-
15 hours ago, David Heffernan said:I'd just read them using the UTF8 encoding in the first place and so never ever see these characters. I'm sure you would too.
That would be my first try too.
Since could just as well be the odd way the PDF to text on-line exporter makes an encoding error (it wouldn't be the first tool or site doing strange encoding stuff, hence the series of blog posts at https://wiert.me/category/mojibake/ ) and why I mentioned ftfy: it's a great tool helping to figure out encoding issues.Looking at https://ftfy.vercel.app/?s=… (and hoping this forum does not mangle that URL) two encode/decode steps are required to fix, so it does not look like a plain "read using UTF8" solution:
s = s.encode('latin-1') s = s.decode('utf-8') s = s.encode('sloppy-windows-1252') s = s.decode('utf-8')-
1
-
-
On 4/4/2023 at 10:57 AM, David Schwartz said:The files have lots of things like ’ and – and … scattered throughout.
I found a table that shows what they're supposed to be and wrote this to convert them (strs points to a memo.Lines property):
Run these oddly looking Mojibake character sequences through ftfy: fixes text for you analyser which lists the encoding/decoding steps to get from the oddly looking text to proper text, then repeat these encoding sequences in Delphi code (using for instance the TEncoding class).
This is way better than using a conversion table, because likely that table will be incomplete.
It also solves your problem where apparently your Delphi source code got mangled undoing your table based conversion workaround.That code mangling can have lots of causes including hard to reproduce bugs of the Delphi IDE itself or plugins used by the IDE.
BTW: if you install poppler (for instance through Chocolatey), the included pdftotext console executable can extract text from PDF files for you.
-
1 hour ago, Mike Torrettinni said:Great! Just a little something they still need to do:
[5e9d67bd4958162e561dcaf6] /CodeExamples/Alexandria/en/Main_Page Wikimedia\Rdbms\DBQueryError from line 1457 of /var/www/html/shared/BaseWiki31/includes/libs/rdbms/database/Database.php: A database query error has occurred. Did you forget to run your application's database schema updater after upgrading?
Query: SELECT lc_value FROM `cde_alexandria_en_l10n_cache` WHERE lc_lang = 'en' AND lc_key = 'deps' LIMIT 1
Function: LCStoreDB::get
Error: 1146 Table 'wikidb.cde_alexandria_en_l10n_cache' doesn't exist (10.50.1.120)That is part of what I mentioned in "Failing: [Archive] Internal error - RAD Studio Code Examples (Alexandria: CodeExamples)"
For now it looks like en/de/fr/ja work for RADStudio and Libraries, but not for Code Examples.
-
There is some progress: response times have become faster (no more 10 seconds to wait for the error 500 response) and some bits of the Alexandria wiki are working.
Working:
- [Wayback/Archive] RAD Studio (Alexandria: RADStudio)
- [Wayback/Archive] RAD Studio API Documentation (Alexandria: Libraries)
Failing: [Archive] Internal error - RAD Studio Code Examples (Alexandria: CodeExamples)
But hey: getting 2 out of the some 42 wikis for the English language (in the mean time I figured out there are 3 wikis for each Delphi version; the actual number is times 4 as there is English, French, German and Japanese) working in some 38 hours is still slow.
From [Wayback/Archive] Docwiki https - EmbarcaderoMonitoring
Response Time Last 2 days
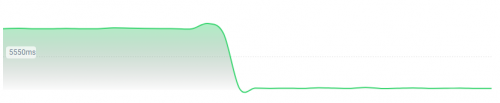
4952.09ms / 11117.00ms / 214.00ms
Avg. response time / Max. response time / Min. response time-
1
-
 1
1
-
-
38 minutes ago, A.M. Hoornweg said:Maybe these servers were outsourced to a country now suddenly under embargo and Idera has been locked out ?
That chance is slim because
DNS records for docwiki.embarcadero.com — NsLookup.io
A records
IPv4 address 204.61.221.12
QUASAR DATA CENTER, LTD.
Location Houston, Texas, United States of America AS AS46785 AS name QUASAR DATA CENTER, LTD. The blog post I wrote thanks to loads of input in this thread: The Delphi documentation site docwiki.embarcadero.com has been down/up oscillating for 4 days is now down for almost a day. « The Wiert Corner – irregular stream of stuff
-
1
-
-
12 hours ago, Remy Lebeau said:It is not just the load balancer that is having issues. For example, trying to access several pages today, I'm running into a new kind of error:
...
Error: 1146 Table 'wikidb.lib_sydney_en_l10n_cache' doesn't exist (10.50.1.120)Whoa, that at first very much confused me thinking there was a data integrity error, but then after realising lib_sydney_en_l10n_cache - Google Search didn't return results I reproduced it with a different one taking some 10 seconds for the request to even get displayed:
Error: 1146 Table 'wikidb.rad_xe8_en_l10n_cache' doesn't exist (10.50.1.120)Besides the very long response time (how slow can a database lookup be?), look at the table names:
-
lib_sydney_en_l10n_cache -
rad_xe8_en_l10n_cache
They have two different prefixes (
libandrad) and two different product codes (sydneyandxe8).This looks like a a setup with each product version having at least two different Wikimedia databases each having an
l10n_cachetable (and likely copies being made for each new product version, which I can understand from a versioning perspective) all integrated in one documentation site.Searching for [Wayback/Archive] l10n_cache - Google Search resulted in [Wayback/Archive] Manual:l10n_cache table - MediaWiki (which describes the table for all ranges of Mediawiki versions) and a whole load of pages with various circumstances in which people bump into missing this table.
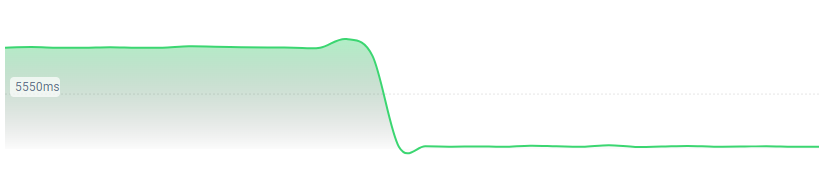
Then I looked at the status monitor [Wayback/Archive] Docwiki https - EmbarcaderoMonitoring - docwiki https where it looks someone started working on it almost 15 hours ago:Response Time Last 2 days

5012.65ms / 10372.00ms / 214.00ms
Avg. response time / Max. response time / Min. response timeRecent events
Down for 14 h, 40 min
The reason is Internal Server Error.500Details:The server encountered an unexpected condition that prevented it from fulfilling the request.March 7, 2022, 17:57 GMT +00:00Running again
March 7, 2022, 17:46 GMT +00:00I really really hope they know what they are doing, as right now the databases don't look well and things have not improved for more than 15 hours (I was interrupted while writing this reply).
--jeroen
-
1
-
-
6 hours ago, Vandrovnik said:I suppose it will be more difficult to find information on docwiki.embarcadero.com using Google, because Google Bot probably most of the time also sees just errors...
This is in part why Meik Tranel offered to host an export of the database. Another part that it is driving people nuts that the only reasonable search index will point to (sometimes cached) pages, but one cannot access them.
Hopefully:
- not all Embarcadero docwiki database servers have issues
- there is recent a back-up that can be restored if they have
Fingers crossed....
-
1
-
-
7 hours ago, A.M. Hoornweg said:No it is not.
Guys, just take a look at the PHP exception trace. More specifically, the line that reads "LoadBalancer->getConnection(0,Array,false)", that's where the shit hits the fan.
That line triggers a "connection refused" exception. One of the servers which the load balancer can choose from in this array is inaccessible.
Not all of them are inaccessible because when you press F5 often enough in your browser the load balancer will sooner or later hit one that works.
So this is a simple web site management issue. The person in charge should simply remove broken db servers from the list which the load balancer uses to choose from.
That last sentence might not be completely true.
Based on the MediaWiki 1.31.1 source code, I drafted a blog post yesterday. It is not published yet as I ran into some WayBackMachine and Archive Today trouble: they are both slow and the Archive Today redirect mentioned at https://blog.archive.today/post/677924517649252352/why-has-the-url-archive-li-changed-to coincided with HTTP-302 redirect loops on my side.This was my conclusion in the blog post is this:
QuoteFailing method is called by the class starting at [Wayback/Archive] .../mediawiki/blob/1.31.1/includes/cache/localisation/LCStoreDB.php - Line 28
Some of the requests succeed, so there seem to be three possibilities:
- Sometimes the load balancer cannot get a database connection at all
- Sometimes the load balancer gets a valid connection and that connection then fails returning a query
- Sometimes the load balancer gets a valid connection and that connection succeeds returning a query
That their largest and most important site is still failing and there is no communication from Embarcadero either on social media or 3rd party forums (they do not have their own forums any more) is inexcusable.
So it might be that it is not a single point of failure, and even underdimensioned might not cut it.
Then to your next excellent question:
7 hours ago, A.M. Hoornweg said:So... Why the heck does Idera not manage this properly?
I have been wondering about this since like forever. Even in the Borland days, uptime was often based on fragility and this has not improved much.
Having no status page is also really outdated. Looking at some TIOBE index languages surrounding Delphi:
- https://status.rubygems.org/
- https://cran.r-project.org/mirmon_report.html
- https://status.mathworks.com/
-
1
-
20 hours ago, DJof SD said:NP. A check of a number of BM's in my browser shows that clicking refresh enough times does eventually result in the desired page shown correctly.
This is true: some of the time it is up.
Over the last 24 hours downtime is "more" than 55% (not the kind of SLA I would be satisfied with, but hey: I'm not Embarcadero IT), see the saved status at https://archive.ph/2HXRI:
Quote56.631%
Last 24 hoursFrom the history on that page (or browsing the live status at https://stats.uptimerobot.com/3yP3quwNW/780058619), you can see that both uptime and downtime periods vary widely between roughly 5 and 90 minutes.
To me that sounds like intermittently failing or underdimensioned hardware.
Hovering over the red bars you see the uptime during the weekend (especially on Sunday) is better than during weekdays. Speculating further, this could have to do with access rates being less during these days.
The non-public status on the UptimeRobot maintenance page shows this graph which has better resolution than the public status page:
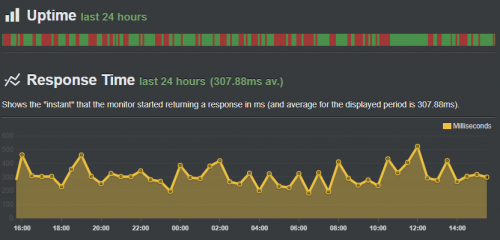
Response times are about twice as large as my blog on WordPress.com, see https://stats.uptimerobot.com/AN3Y5ClVn/778616355
I have also modified my docwiki http check to use deeper page (instead of the home page). That monitor is at https://stats.uptimerobot.com/3yP3quwNW/780058617Let's see what the monthly average will be some 30 days from now.
--jeroen
-
2 hours ago, DJof SD said:Thanks for the explanation.
What I thought odd was the exact same percentages were posted for all 4 time periods. I would have guessed all 4 values would have been different. But I'll assume that the free plan is the limiting factor and the explanation for that sameness being seen.
It is indeed confusing. In 30 days it should all be "clear".
When you look at the event history of that monitoring page (I saved it at https://archive.ph/RNeuP) and you see that it is oscillating between down and up. Since the free monitoring is only every 5 minutes, the oscillation appears a very regular interval which might not be that regular.
Being up part of the time, that will also likely influence these numbers.
I also searched and found back where I originally created the monitoring pages https://stats.uptimerobot.com/3yP3quwNW (there are close to 50 of them, but I did not keep track of which sites went permanently down as there is no clear documented Embarcadero provided list of them).
The original article was at https://wiert.me/2022/01/19/some-uptime-monitoring-tools-that-are-still-free-and-understand-more-than-http-https which I started writing at 20210528. The monitors themselves are way older: I tracked them back in my email archive to February 2018, so slightly more than 4 years ago. -
1 hour ago, DJof SD said:That monitor is nice but how can these numbers be correct?
As the free plan is limited to 50 entries, I redirected an existing monitor to the new URL () then turned it on. My guess is that even while the old URL was turned off off, it was counted as "up", and reflected in these numbers.
The numbers are already going down, as while writing it is this from the ~53% you noticed:
Quote39.050%
Last 24 hours39.050%
Last 7 days39.050%
Last 30 days39.050%
Last 90 days--jeroen
-
1
-
-
59 minutes ago, Vandrovnik said:It says it cannot connect to MySQL database server, so the problem would probably happen with newer MediaWiki, too.
The MySQL uptime and the connection to are still responsibilities of the IT department.
Anyway: made it UptimeRobot watch a deeper link which is now available at https://stats.uptimerobot.com/3yP3quwNW/780058619 for anyone to keep an eye on.
Luckily, https://web.archive.org and https://archive.is have a lot of pages archived.-
1
-
-
It's flaky. Again.
I archived https://archive.ph/TIWRy from https://docwiki.embarcadero.com/RADStudio/Alexandria/en/Main_Page:[8c1240dd3d6ee2e766657d26] /RADStudio/Alexandria/en/Main_Page Wikimedia\Rdbms\DBQueryError from line 1457 of /var/www/html/shared/BaseWiki31/includes/libs/rdbms/database/Database.php: A connection error occured. Query: SELECT lc_value FROM `rad_alexandria_en_l10n_cache` WHERE lc_lang = 'en' AND lc_key = 'preload' LIMIT 1 Function: LCStoreDB::get Error: 2006 MySQL server has gone away (etnadocwikidb01) Backtrace: #0 /var/www/html/shared/BaseWiki31/includes/libs/rdbms/database/Database.php(1427): Wikimedia\Rdbms\Database->makeQueryException(string, integer, string, string) #1 /var/www/html/shared/BaseWiki31/includes/libs/rdbms/database/Database.php(1200): Wikimedia\Rdbms\Database->reportQueryError(string, integer, string, string, boolean) #2 /var/www/html/shared/BaseWiki31/includes/libs/rdbms/database/Database.php(1653): Wikimedia\Rdbms\Database->query(string, string) #3 /var/www/html/shared/BaseWiki31/includes/libs/rdbms/database/Database.php(1479): Wikimedia\Rdbms\Database->select(string, string, array, string, array, array) #4 /var/www/html/shared/BaseWiki31/includes/cache/localisation/LCStoreDB.php(52): Wikimedia\Rdbms\Database->selectField(string, string, array, string) #5 /var/www/html/shared/BaseWiki31/includes/cache/localisation/LocalisationCache.php(357): LCStoreDB->get(string, string) #6 /var/www/html/shared/BaseWiki31/includes/cache/localisation/LocalisationCache.php(271): LocalisationCache->loadItem(string, string) #7 /var/www/html/shared/BaseWiki31/includes/cache/localisation/LocalisationCache.php(471): LocalisationCache->getItem(string, string) #8 /var/www/html/shared/BaseWiki31/includes/cache/localisation/LocalisationCache.php(334): LocalisationCache->initLanguage(string) #9 /var/www/html/shared/BaseWiki31/includes/cache/localisation/LocalisationCache.php(371): LocalisationCache->loadItem(string, string) #10 /var/www/html/shared/BaseWiki31/includes/cache/localisation/LocalisationCache.php(292): LocalisationCache->loadSubitem(string, string, string) #11 /var/www/html/shared/BaseWiki31/languages/Language.php(3177): LocalisationCache->getSubitem(string, string, string) #12 /var/www/html/shared/BaseWiki31/includes/MagicWord.php(352): Language->getMagic(MagicWord) #13 /var/www/html/shared/BaseWiki31/includes/MagicWord.php(280): MagicWord->load(string) #14 /var/www/html/shared/BaseWiki31/includes/parser/Parser.php(4848): MagicWord::get(string) #15 /var/www/html/shared/BaseWiki31/extensions/TreeAndMenu/TreeAndMenu_body.php(24): Parser->setFunctionHook(string, array) #16 /var/www/html/shared/BaseWiki31/includes/Setup.php(948): TreeAndMenu->setup() #17 /var/www/html/shared/BaseWiki31/includes/WebStart.php(88): require_once(string) #18 /var/www/html/shared/BaseWiki31/index.php(39): require(string) #19 {main}The main page gives a HTTP 404, but also loads https://docwiki.embarcadero.com/RADStudio/Alexandria/e/load.php?debug=false&lang=en&modules=ext.fancytree%2Csuckerfish|jquery.accessKeyLabel%2CcheckboxShiftClick%2Cclient%2Ccookie%2CgetAttrs%2ChighlightText%2Cmw-jump%2Csuggestions%2CtabIndex%2Cthrottle-debounce|mediawiki.RegExp%2Capi%2Cnotify%2CsearchSuggest%2Cstorage%2Cuser|mediawiki.api.user|mediawiki.page.ready%2Cstartup|site|skins.duobook2.js&skin=duobook2&version=149306z which delivers a nice 500.
A long time ago I made https://stats.uptimerobot.com/3yP3quwNW for monitoring http(s) status in the hope they would be watching it.
That one monitors the home page, but maybe I should have it monitor a sub-page like the main page for XE8 or so, as this one also gives a nice 500 error: https://docwiki.embarcadero.com/RADStudio/XE8/en/Main_Page
On the other hand: from a bigger organisation like Idera, one would exepct more IT infrastructure competence (hello 24x7 monitoring!) than back in the days when just the core CodeGear DevRel team was keeping the documentation sites up and running (and by using Delphi web front-end plus InterBase database back-end provided valuable quality feed back to the R&D team).
Guessing from `BaseWiki31` I guessed they might still be on MediaWiki 1.31 which was an LTS version, but is unsupported now and has been replaced by 1.35 LTS.
My guess was right as in https://docwiki.embarcadero.com/ (archived as https://web.archive.org/web/20220217084835/http://docwiki.embarcadero.com/) you see this:<meta name="generator" content="MediaWiki 1.31.1">
MediaWiki versions are at:
- https://www.mediawiki.org/wiki/MediaWiki_1.31
- https://www.mediawiki.org/wiki/MediaWiki_1.35
- https://www.mediawiki.org/wiki/Version_lifecycle
Back in the days they were keen in advocating life cycle management. Maybe time to show they indeed still understand what that means.
--jeroen
-
1
-
-
Not sure which of the subforums to post, but here it goes:
With great sadness, I just got word from both Julian Bucknall on Twitter and Lino Tadros on Facebook that my dear friend Danny Thorpe passed away on October 22nd, just a few hours ago.
Still limited in energy, still recovering from many treatments, I will need to keep it short and hope to gain some more energy and blog a small obituary later.
For now, I'm devastated. Loosing a friend and one of the instrumental Delph R&D team members from the days brings so many mixed emotions.
I wish his wife Cindy and their loved ones all the best.
Rest in peace dear Danny. The world will be different without you.
--jeroen
Referencs:- https://twitter.com/JMBucknall/status/1451674438097854464, https://twitter.com/jpluimers/status/1451677770552123399
- https://www.facebook.com/lino.tadros/posts/10158270097971179, https://www.facebook.com/cindy.f.thorpe/posts/10224108253026657
-
6
-
3
-
 14
14
-
-
The best open source Delphi parser I know is DelphiAST. It is the foundation https://www.tmssoftware.com/site/fixinsight.asp which catches way more code issues than the Delphi compiler itself does.
DelphiAST gets you an abstract syntax tree. Code is at https://github.com/RomanYankovsky/DelphiAST
-
3
-
-
You can write an IDE plugin for this that switches to the existing instance, then quits the new one.
But first you have to define "single instance", and how to set instances apart.
For instance, I know many Delphi developers that run Delphi with various registry tree starting points. Or run one with admin privileges and the other without. Or run one as user A and another as user B. Are those different instances?
A much simpler trick might be to look at the windows task bar: is there already a Delphi icon on it? Click on it and see which instances are running.
-
I am trying to track down a problem while loading PNGs that happens, but hardly, on a few end-user sites.
The crash is inside this piece of code in Delphi 10.1 Berlin unit Vcl.Imaging.pngimage.pas :
{Resizes the image data to fill the color type, bit depth, } {width and height parameters} procedure TChunkIHDR.PrepareImageData(); //... {Create the device independent bitmap} ImageHandle := CreateDIBSection(ImageDC, pBitmapInfo(@BitmapInfo)^, DIB_RGB_COLORS, ImageData, 0, 0); SelectObject(ImageDC, ImageHandle); {Build array and allocate bytes for each row} fillchar(ImageData^, BytesPerRow * Integer(Height), 0); end;The VCL code has diverged from for instance https://github.com/thargor6/mb3d/blob/master/pngimage.pas and http://svn.hiasm.com/packs/delphi/code/KOLPng.pas but similar to http://www.gm-software.de/units/GMPngImage.htm (the three highest deduplicated search hits I got for "TChunkIHDR.PrepareImageData" "fillchar")
What happens here is that the call to CreateDIBSection is not verified to succeed. Documentation indicates that if it fails, both the returned ImageHandle are the ImageData pointer are null.
I am trying to get the calling code refactored so it saves the PNG file, hoping that it will help tracking back the actual root-cause of this problem.
One question I now have if people have bumped into similar problems.
Of course this is a problem involving multiple libraries, in this case at least FastReport and wPDF, as you can see from the below part of the not-fully-accurate (I think the FastFreeMem is bogus) stack trace:
[008080E5]{MyApplication.exe} JclHookExcept.HookedExceptObjProc (Line 391, "JclHookExcept.pas" + 2) [0040B54F]{MyApplication.exe} System.@HandleAnyException (Line 19565, "System.pas" + 13) [009894E5]{MyApplication.exe} Vcl.Imaging.pngimage.TChunkIHDR.PrepareImageData (Line 2311, "Imaging\PNGImage\Vcl.Imaging.pngimage.pas" + 67) [00989099]{MyApplication.exe} Vcl.Imaging.pngimage.TChunkIHDR.LoadFromStream (Line 2162, "Imaging\PNGImage\Vcl.Imaging.pngimage.pas" + 48) [0098D4C4]{MyApplication.exe} Vcl.Imaging.pngimage.TPngImage.LoadFromStream (Line 4904, "Imaging\PNGImage\Vcl.Imaging.pngimage.pas" + 71) [01994896]{MyApplication.exe} frxClass.TfrxPictureView.LoadPictureFromStream (Line 6574, "frxClass.pas" + 141) [00420BDF]{MyApplication.exe} FastMM4.FastFreeMem (Line 5644, "FastMM4.pas" + 18) [019348E2]{MyApplication.exe} frxPictureCache.TfrxMemoryStream.Seek (Line 351, "frxPictureCache.pas" + 4) [004CE682]{MyApplication.exe} System.Classes.TStream.SetPosition (Line 7306, "System.Classes.pas" + 1) [01934443]{MyApplication.exe} frxPictureCache.TfrxPictureCache.GetPicture (Line 213, "frxPictureCache.pas" + 24) [0194D521]{MyApplication.exe} frxPreviewPages.DoObjects (Line 1277, "frxPreviewPages.pas" + 13) [0194D540]{MyApplication.exe} frxPreviewPages.DoObjects (Line 1281, "frxPreviewPages.pas" + 17) [0194D755]{MyApplication.exe} frxPreviewPages.TfrxPreviewPages.GetPage (Line 1341, "frxPreviewPages.pas" + 56) [01A68E3A]{MyApplication.exe} wPDF.FastReportNaarWPDF$0$ActRec.$1$Body (Line 282, "wPDF.pas" + 21) [01A6888C]{MyApplication.exe} MemoryManager.TLogMemoryStatesHelper.LogMemoryStatesBeforeAndAfter (Line 797, "MemoryManager.pas" + 14) -
2 hours ago, Markus Kinzler said:From https://www.habarisoft.com/index.html#faq :
QuoteNo, AMQP and MQTT are not supported. The library only supports the STOMP wire format.
1 hour ago, Frédéric said:The question asked specifically for 1.0, as 0.9.1 is a totally different protocol: https://www.rabbitmq.com/protocols.html
QuoteAMQP 1.0
Despite the name, AMQP 1.0 is a radically different protocol from AMQP 0-9-1 / 0-9 / 0-8, sharing essentially nothing at the wire level. AMQP 1.0 imposes far fewer semantic requirements; it is therefore easier to add support for AMQP 1.0 to existing brokers. The protocol is substantially more complex than AMQP 0-9-1, and there are fewer client implementations.
3 hours ago, toms said:There's a 30-Day Fully-Functional Free Trial and some demos.
Thanks. I will give that a try later on.
-
1 hour ago, Fesih ARSLAN said:There is a paid library developed for this purpose.
The component set has MQTT and AMQP support.
Thanks. Do you have any experience with it? If so, how well is their implementation?
I know that last question is hard to estimate, as I could not find AMQP test suites. -
Since not all Message Oriented Middleware does STOMP, I wonder if there is an AMQP 1.0 compatible Delphi library around, either open source or commercial.
A Google Search did not reveal many results, and the ones I found were kind of vague on the versions of AMQP that is implemented.
Any tips?
-
I have given this some thought. My main aim is to follow in a central place like feedly.com without re-creating a new RSS feed for everything i want to follow.
Basically my G+ was the central place to follow all my social media stuff, and feedly.com is my place for following news.
Any thoughts on that?
-
I could use some input on https://gist.github.com/jpluimers/b08b65991987d01e1dd1bdb4bf8a33c4
Especially on:
- the abstracting of the non-UI logic from https://github.com/pleriche/FastMM4/blob/master/Demos/Usage Tracker/FastMMUsageTracker.pas
- the conversion to JSON: built-in Delphi JSON support does not do records out of the box, but I feel my workaround is cumbersome.There is an example on how to use it for logging memory and processor usage on the console.
-
One of the strengths of G+ is that you can follow posts (by commenting on them) so you get notifications on new comments.
This allows a way of operation where you see just two things in a post feeds:
- new posts
- posts re-appear that you commented on and have new comments since the last comment
This was a very powerful way of keeping up, with things and one of the reasons I limited myself almost exclusively to G+ (forums, Twitter, FaceBook, do not have this).
Is it possible to have a forum stream that comes close to the above behaviour?
The current RSS stream does not: it gets an entry for every new post or comment.
--jeroen

Delphi MT940 implementation (reader, writer)
in Algorithms, Data Structures and Class Design
Posted
The C# library Raptorious.Finance.Swift.Mt940 has been ported 5 years ago to .NET core at https://github.com/mjebrahimi/SharpMt940Lib.Core/tree/master
I have used the raptorious one to successfully parse ABN AMRO MT940 files and convert them to CD at https://github.com/jpluimers/MT940-to-CSV
It should be relatively straightforward to port them to Delphi.
--jeroen