
Zacherl
-
Content Count
23 -
Joined
-
Last visited
Posts posted by Zacherl
-
-
25 minutes ago, David Heffernan said:That's what you said.
It's okay man. Can't help it, if you don't want to read the complete post (e.g. the text i quoted from the Intel SDM). I'm out.
-
2 minutes ago, David Heffernan said:You said nothing about cache lines.
20 hours ago, Zacherl said:Unaligned 16-, 32-, and 64-bit accesses to cached memory that fit within a cache line
Nothing more to say ...
-
1 hour ago, Primož Gabrijelčič said:If there is a writer - does it have to be writing with 'lock' prefix or no?
You will need a lock prefix only, if you have concurrent threads reading, modifying (e.g. incrementing by one) and writing values. This is to make sure the value does not get changed by another thread in a way like this:
T1: read 0
T2: read 0
T2: inc
T2: write 1
T1: inc
T1: write 1
By locking that operation, read + increment + write is always performed atomic:
T1: read 0
T1: inc
T1: write 1
T2: read 1
T2: inc
T3: write 2
For forther explanation read this:
6 hours ago, Zacherl said:For multi threaded read-modify-write access, read this (TLDR: you will need to use `TInterlocked.XXX()`):
If you only want to write values without reading and modifying of the previous value, no `LOCK` prefix is needed.
-
51 minutes ago, Primož Gabrijelčič said:I can confirm (from experience) that this is indeed true. I cannot find any definitive document about that, but it looks like since 2011/12 unaligned access doesn't hurt very much (at least on Intel platform).
Well, okay seems like the Intel SDM needs to be updated. Did anybody test the same szenario with multi-threaded atomic write operations (`lock xchg`, `lock add`, and so on)? Could imagine different results in terms of performance here.
Anyways .. I guess the original question is answered. To summarize this:
- 1 byte reads are always atomic
- 2/4/8 byte reads are atomic, if executed on a P6+ and fitting in a single cache line (any sane compiler should use correct alignments by itself)
For multi threaded read-modify-write access, read this (TLDR: you will need to use `TInterlocked.XXX()`):
-
 1
1
-
4 hours ago, David Heffernan said:Actually both of these statements are wrong. Reading unaligned memory is not atomic for reads that straddle cache lines.
Sorry, but did you actually read my post?
Thats exactly what I quoted from the latest Intel SDM:
13 hours ago, Zacherl said:• Unaligned 16-, 32-, and 64-bit accesses to cached memory that fit within a cache line
4 hours ago, David Heffernan said:And unaligned memory access is not slow on modern processors.
Can you please give me some references that proof your statement? Intel SDM says (you might be correct for normal data access, but using the `LOCK` prefix is something else):
13 hours ago, Zacherl said:nonaligned data accesses will seriously impact the performance of the processor and should be avoided.
-
Reading unaligned values from memory is slow but should still be atomic (on a Pentium6 and newer). This behavior is described in the Intel SDM:
Quote8.1.1 Guaranteed Atomic Operations
The Intel486 processor (and newer processors since) guarantees that the following basic memory operations will
always be carried out atomically:
• Reading or writing a byte
• Reading or writing a word aligned on a 16-bit boundary
• Reading or writing a doubleword aligned on a 32-bit boundary
The Pentium processor (and newer processors since) guarantees that the following additional memory operations
will always be carried out atomically:
• Reading or writing a quadword aligned on a 64-bit boundary
• 16-bit accesses to uncached memory locations that fit within a 32-bit data bus
The P6 family processors (and newer processors since) guarantee that the following additional memory operation
will always be carried out atomically:
• Unaligned 16-, 32-, and 64-bit accesses to cached memory that fit within a cache lineThe above is only valid for single-core CPUs. For multi-core CPUs you will need to utilize the "bus control signals" (click here for explanation) :
QuoteAccesses to cacheable memory that are split across cache lines and page boundaries are not guaranteed to be atomic by the Intel Core 2 Duo, Intel® Atom™, Intel Core Duo, Pentium M, Pentium 4, Intel Xeon, P6 family, Pentium, and Intel486 processors. The Intel Core 2 Duo, Intel Atom, Intel Core Duo, Pentium M, Pentium 4, Intel Xeon, and P6 family processors provide bus control signals that permit external memory subsystems to make split accesses atomic; however, nonaligned data accesses will seriously impact the performance of the processor and should be avoided.
Delphi implements the System.SyncObjs.TInterlocked class which provides some functions to help with atomic access (e.g. `TInterlocked.Exchange()` for an atomic exchange operation). You should always use these functions to make sure your application does not run into race conditions on multi-core systems.
BTW: I released an unit with a few atomic type wrappers some time ago (limited functionality compared to the `std::atomic<T>` C++ types as Delphi does not allow overloading of the assignment operator):
https://github.com/flobernd/delphi-utils/blob/master/Utils.AtomicTypes.pas
-
43 minutes ago, David Heffernan said:Why don't you override the method from TObject?
That's exactly the problem and as well the reason for the warning. The OP does not actually override TObject.ToString but introduces a new method (because of the different signature). The override just does nothing.
-
14 hours ago, Kryvich said:The best way to fix a bug is to identify it as early as possible. I use asserts to validate the input parameters of subroutines, to verify the result of a function, and sometimes inside a subroutine if needed. Asserts always enabled during development, at alpha and beta testing stages. After release, they can be disabled if they noticeably affect the speed of the application.
You are correct ofc, but assertions are only used to detect programming errors (should be at least ^^) and allow for advanced tests like fuzzing, etc. They should in no case be used as a replacement for runtime exceptions. If a runtime exception occurs on a productive system, you need a real logging functionality included in your product to be able to reproduce the bug (independently of the assertions, which are always good to have 🙂 ).
There is madExcept and stuff like that which will provide you callstacks in case of a runtime exception, but sometimes event that is not sufficient (e.g. in cases where code fails silently without exception and so on).
-
Just now, Juan C.Cilleruelo said:This is my current code. I think now is working well.
Should work 👍 Was just about to recommend adding an additional timeout to the code, but you already did with your error counter 🙂
-
I remember a that that discussed a similar topic .. it was something like "How to detect, if I can append data to a file". The solution was: Try it and catch errors. There are just too many variables that you would have to check (file exists, access privileges, exclusive access, ...).
If you need cross-platform, I can just quote myself:
3 hours ago, Zacherl said:Just trying to open the file is already the correct solution IMHO. You should catch the exception and retry until it works.
There are other approaches, if cross-platform support is not needed, but none of them are easy (on Windows you could enumerate all open handles to the file e.g. or work with global `CloseHandle` hooks).
-
 1
1
-
-
Isn't the optimizer smart enough to remove empty function calls? Well ... I know ... it's Delphi ... and Delphi is not really known for perfectly optimized code, but detecting empty functions is a really easy task. Using `IFDEF`s inside the logging function itself would be a better solution in this case.
Edit;
2 minutes ago, Zacherl said:Isn't the optimizer smart enough to remove empty function calls?
Well tested it, and ... ofc it does not eliminate calls to empty functions
 Generates a `CALL` that points to a single `RET` instruction instead. This should not happen in 2018.
Generates a `CALL` that points to a single `RET` instruction instead. This should not happen in 2018.
-
Assert is fine, but sometimes you want to have logging code in your productive version. Asserting is not a good idea here as it will raise an exception. Besides that only one event can be logged at a time (as the application crashes after the first assertion / or executes the exception handler what will them prevent execution of successive assertions).
-
Just trying to open the file is already the correct solution IMHO. You should catch the exception and retry until it works.
-
1
-
-
5 hours ago, Kryvich said:As a side note:
... mov [ebp-$04],eax mov eax,[ebp-$04] // <--- ??? call @UStrAddRef ...
Compiler optimization is on. There is a place for optimizations. 😉
This shitty code has been generated for ages now. Don't think they will ever fix this.
-
Looks like SSL handshake takes the most time (for both sites tho):
http://www.bytecheck.com/results?resource=https%3A%2F%2Fwww.delphipraxis.net
http://www.bytecheck.com/results?resource=https%3A%2F%2Fen.delphipraxis.net
More detailed:
https://www.webpagetest.org/result/181030_JQ_267f61dbcfda23a4de5efaff62bb54c3/
https://www.webpagetest.org/result/181030_HC_87ad088dd0cbeff086ae2c78f9231136/
-
1 minute ago, Markus Kinzler said:The data to be transfered is also higher. The delay from the js stuff adds extra time.
Jup, might be the problem. But as I said: No big deal at all. Just noticed that.
Frontpage (first one = DE, second one = EN):
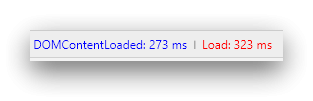
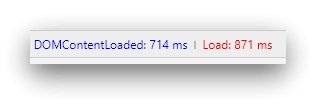
Random thread (first one = DE, second one = EN):
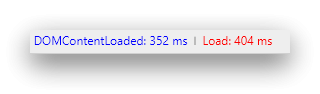
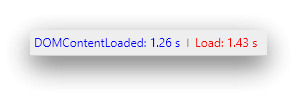
-
1 minute ago, Markus Kinzler said:The JavaScript part seems much mory complex. The difference between vBulletin ( german) and IPS (here) is higher on less powerfull machines.
As I said: I only measured the pure network load times, not the CPU/Render/JS stuff. Ok, some content might be loaded by JS, but my machine is not slow at all. i9-7900X @ 4.6GHz, 64GiB RAM, Samsung SSD 950 Pro. I'm going to upload some screenshots.
-
4 minutes ago, Markus Kinzler said:It depend also on the local machine.
Sure, but both times were measured on the same machine. The German DP has an average load time of 350ms for me while the Englisch DP takes 1300 seconds to load. This is what the Chrome "Network" graph tells me (pure network load time, without any render/CPU related delays).
-
I noticed a rather slow performance as well (compared to the german DP). Assuming both forums beeing hosted on the same server cluster, I have to guess that the new board software just adds a little bit of overhead. But no big deal for me 🙂
Custom Managed Records Coming in Delphi 10.3
in RTL and Delphi Object Pascal
Posted
The var can actually make sense, if you think of the C++ move semantics. This way you could either implement a copy or a move assignment operator ... Would be nice if there was a way to implement both (same for constructors).