

Anders Melander
-
Content Count
2265 -
Joined
-
Last visited
-
Days Won
117
Posts posted by Anders Melander
-
-
1 hour ago, Attila Kovacs said:Wow, from now on, you can open the same file multiple times.
You have been able to do that in Delphi for 10-15 years - Just not with both editors docked.
-
8 hours ago, A.M. Hoornweg said:COM was used by IDE's such as Visual Basic to host (in-process) VBX controls but it works across processes as well.
With in-process COM you'd have all the same problems without any of the benefits of the BPL/DLL packages.
With out-of-process COM you'd have the benefit of process separation but you would have to surface the whole TControl and design-time API bidirectionally. It would be a nightmare. Also each process would contain their own linked-in copy of the RTL/VCL.
And forget about shoehorning this into the existing IDE; It would have to be rewritten from scratch.
No thanks.
-
Just now, A.M. Hoornweg said:My preference would be to have the component packages in separate helper processes.
Yes, that much was clear. So how do you accomplish that?
-
You can use OpenCV on Android and iOS.
Haven't you researched this at all?
-
1 hour ago, A.M. Hoornweg said:This means that moving away from 32-bit x86 would be a huge breaking change for the deployment of third party components.
No more than any other major upgrade of Delphi.
1 hour ago, A.M. Hoornweg said:Frankly, I've never understood why the design time packages are hosted in the IDE process itself because bugs in components will affect the IDE.
How would you have designed the system then?
-
 1
1
-
-
I think you can safely assume that:
- GlobalSize returns the correct size.
- Any additional memory it might return (which I don't believe it will) will be zeroed.
I've been working with drag/drop and the clipboard through COM for 25 years and none of my tools has any handling of extra data and they assume that GlobalSize returns the requested size (which is has so far).
-
1
-
GlobalSize isn't useless just because it doesn't behave the way you want it to or expect it to.
From what I can tell you can only rely on the returned size to be >= requested size. Regardless of whatever it might return right now on your system.
That said, I can't remember having GlobalSize return a value I didn't expect - but I might also just have forgotten about it.
Anyway, if you are reading data from the clipboard then you can try to request the TYMED_ISTREAM medium instead of TYMED_HGLOBAL. If you are lucky the returned IStream will report the correct size. I doubt it though; I think the IStream is just a wrapper around a HGLOBAL.
-
2 hours ago, pcoder said:And I cannot believe that MS made such a mistake but has not corrected this.
What mistake is that? It's by design. Did you not read the articles you linked to?
-
1 hour ago, Attila Kovacs said:I read something in so from you but I can't find it, it was about the whole rtl float handling is rubbish or something like that. Not sure about the details.
Opinions are easy. Code... a bit harder.
-
 1
1
-
-
-
1 hour ago, Lars Fosdal said:Fun observations on the GoTo topic: https://jerf.org/iri/post/2024/goto/
QuoteWhen I see modern code that uses
goto, I actually find that to be a marker that it was probably written by highly skilled programmers.True, but don't say that out loud.
sEE, i'M uSiNg GoToS; iM A hiGhLy SkIlLeD pRoGraMmEr!
-
1
-
-
40 minutes ago, David Heffernan said:I remember making a bunch of changes based on such benchmarks and then finding absolutely no impact in the actual program, presumably because the bottleneck was memory.
Sounds like premature optimization 🙂
I'm doing graphics so memory bandwidth is always going to be a bottleneck. The first goal then is to use the correct algorithms and update as little as possible (thus minimizing the impact of that bottleneck) and then do everything else as fast as possible. Round and Trunc are used a lot for some operations and while replacing them with something faster might not yield much in most situations they are significant components in some performance scenarios. Also, my goal wasn't really to create a killer Round/Trunc function. I just wound up there because I needed to isolate the functionality when it didn't behave as I expected.
-
2 hours ago, pcoder said:BTW, have you also measured the impact of type?
No. I'm working in Single precision so there's no type conversion going on.
That said, I have implemented overloads for both Single and Double and the single and double instructions performs exactly the same.
-
Ah, our old enemy: Copy/paste
-
I just looked at my unit test of FastTrunk and I wondered why I was running the tests with different values of MXCSR set - and then I remembered why I chose to use ROUNDSS instead of CVTTSS2SI...
The Intel documentation on CVTTSD2SI states:
QuoteWhen a conversion is inexact, the value returned is rounded according to the rounding control bits in the MXCSR register.
So I assumed that CVTTSS2SI behaved the same way and opted against having to fiddle with MXCSR in order to guarantee truncation.
Well, it turns out that it does behave the same way; The documentation wrong. How about that.
-
20 hours ago, Stefan Glienke said:- Spring.Benchmark still has some issues when running on Intels hybrid CPUs (12th and 13th gen) - I can trick a bit with setting Thread Affinity masks to run only on P-Cores but sometimes the times are a bit off
I couldn't find a function for disabling the Efficiency-cores in your public source... so I wrote one (yes, I'm procrastinating again):
// Set process affinity to exclude efficiency cores function SetPerformanceAffinityMask(Force: boolean = False): boolean; procedure RestoreAffinityMask;
Now I just need a CPU that can actually utilize it 😕
By the way, your previous post lead me to this: https://www.uops.info/table.html
Much easier to use than Agner Fog's tables and also appears to be more up to date. Now I'm thinking about how to get that info integrated into the Delphi debugger... and maybe throw in the data from Félix Cloutier's x86 reference. I guess that is also where godbolt gets its reference info from. Oh wait; There I go again. Better get back to work now. -
2 hours ago, Stefan Glienke said:consult the instruction timings table
Unfortunately it isn't up to date. For example, your processor architecture (Raptopr Lake/Raptor Cove) isn't in there.
And, unless you're Peter Cordes and have all this info in your head, it's often too time consuming to compare the timings of each instruction for each of the relevant architectures. And then there's execution units, pipelines, fusing and stuff I don't even understand to consider. Somebody train an AI to figure this sh*t out for me.I seem to remember that VTune had a static code analyzer with all this information built in, many, many versions ago, but I think that's gone now.
2 hours ago, Stefan Glienke said:on x64 we might experience the behavior of implicitly converting Single to Double and back - I did not inspect the assembly code.
Random returns a Double so there conversion from that to Single but that is the same for all the functions. There's no implicit conversion beyond that; If I'm passing a Single to a function that takes a Single argument then that value stays a Single. Passed on the stack for x86 and in XMM0 for x64.
2 hours ago, Stefan Glienke said:(*) code alignment or address of the measured functions being one of the many reasons that can easily make some small or significant differences in the results
I have {$CODEALIGN 16} in an include file as I need it elsewhere for SIMD aligned loads.
2 hours ago, Stefan Glienke said:Take these results with a grain of salt
Yes; Your x64 results are pretty wonky.
ROUNDSS+CVTSS2SI should be faster than CVTSS2SD+CVTTSD2SI.Actually, ROUNDSS+CVTSS2SI has a slightly higher latency (8+6) than CVTSS2SD+CVTTSD2SI (5+6). -
By the way, the reason why the RTL Trunc is slower is probably because it's only been implemented for Double; There is no overload for Single so it always incurs the overhead of Single->Double conversion.
The x64 version is implemented with a single CVTTSD2SI instruction while the x86 version uses x87.
Also, since the RTL Trunc is implemented as assembler it cannot be inlined and on x86 Delphi always pass Single params on the stack even though they would fit in a general register. This levels the playing field and makes a faster alternative worthwhile.
It's beyond me why they haven't implemented basic numerical functions such as Trunc, Round, Abs, etc. as compiler intrinsics so we at least can get them inlined.
-
1
-
-
2 hours ago, Stefan Glienke said:Isn't this all that is needed?
function FastTrunc(Value: Single): Integer; asm {$IFDEF CPUX86} movss xmm0, Value {$ENDIF} cvttss2si eax, xmm0 end;
Yes it is but for some reason CVTTSS2SI is not always faster than CVTSS2SI. I'm not sure that I can trust the benchmarks though. The results does seem to fluctuate a bit.
Here are the different versions (TFloat = Single):
function Trunc_Pas(Value: TFloat): Integer; begin Result := Trunc(Value); end; function FastTrunc_SSE2(Value: TFloat): Integer; asm {$if defined(CPUX86)} MOVSS XMM0, Value {$ifend} CVTTSS2SI EAX, XMM0 end; function SlowTrunc_SSE2(Value: TFloat): Integer; var SaveMXCSR: Cardinal; NewMXCSR: Cardinal; const // SSE MXCSR rounding modes MXCSR_ROUND_MASK = $FFFF9FFF; MXCSR_ROUND_NEAREST = $00000000; MXCSR_ROUND_DOWN = $00002000; MXCSR_ROUND_UP = $00004000; MXCSR_ROUND_TRUNC = $00006000; asm XOR ECX, ECX // Save current rounding mode STMXCSR SaveMXCSR // Load rounding mode MOV EAX, SaveMXCSR // Do we need to change anything? MOV ECX, EAX NOT ECX AND ECX, MXCSR_ROUND_TRUNC JZ @SkipSetMXCSR // Skip expensive LDMXCSR @SetMXCSR: // Save current rounding mode in ECX and flag that we need to restore it MOV ECX, EAX // Set rounding mode to truncation AND EAX, MXCSR_ROUND_MASK OR EAX, MXCSR_ROUND_TRUNC // Set new rounding mode MOV NewMXCSR, EAX LDMXCSR NewMXCSR @SkipSetMXCSR: {$if defined(CPUX86)} MOVSS XMM0, Value {$ifend} // Round/Trunc CVTSS2SI EAX, XMM0 // Restore rounding mode // Did we modify it? TEST ECX, ECX JZ @SkipRestoreMXCSR // Skip expensive LDMXCSR // Restore old rounding mode LDMXCSR SaveMXCSR @SkipRestoreMXCSR: end; function FastTrunc_SSE41(Value: TFloat): Integer; const ROUND_MODE = $08 + $03; // $00=Round, $01=Floor, $02=Ceil, $03=Trunc asm {$if defined(CPUX86)} MOVSS xmm0, Value {$ifend} ROUNDSS xmm0, xmm0, ROUND_MODE CVTSS2SI eax, xmm0 end;
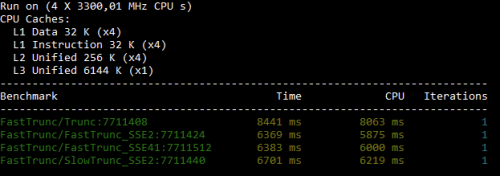
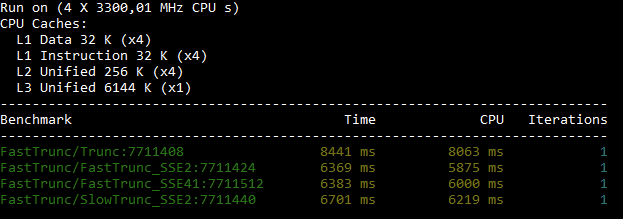
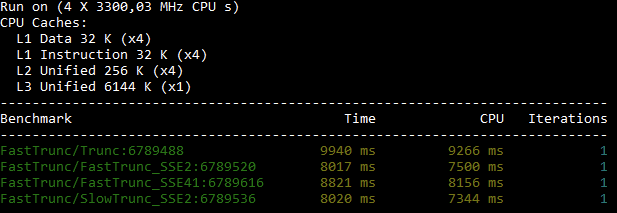
And here are the benchmark results from my 10 year old Core i5-2500K @3.3 desktop system.
x86 results
x64 results
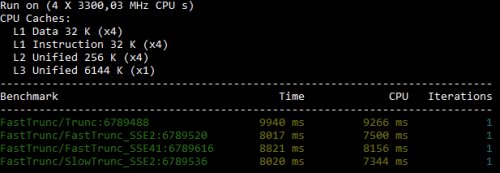
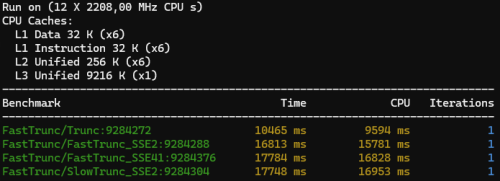
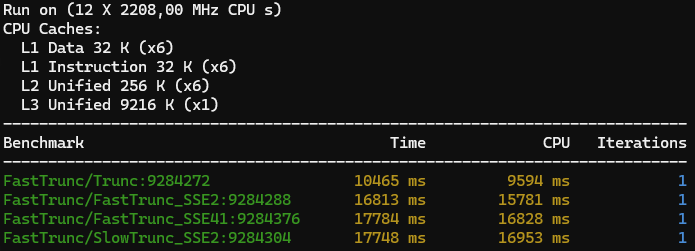
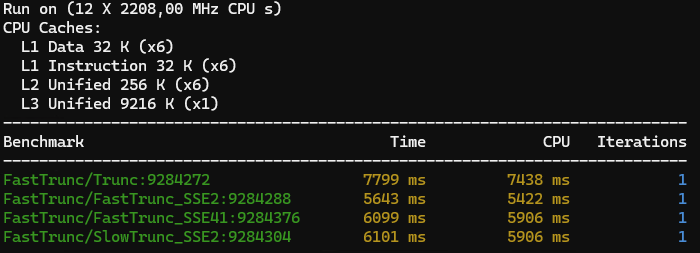
Meh... but at least they are all consistently faster than Trunc - Unless I test on my laptop with a Core i7-8750H CPU @2.2
x86 results on battery
x86 results on mains
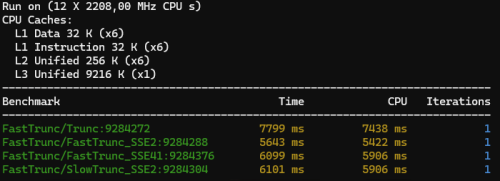
Yes, I know it's the result of my power saving profile throttling the CPU but it's interesting that it makes the x87 math so much faster than the SIMD math.
Here's the benchmark code for completeness:
procedure BM_FastTrunc(const state: TState); begin var FastTruncProc: TFastRoundProc := TFastRoundProc(state[0]); for var _ in state do begin RandSeed := 0; for var i := 1 to 1000*1000*1000 do begin FastTruncProc(Random(i) / i); end; end; end; const FastTruncs: array[0..3] of record Name: string; Proc: TFastRoundProc; end = ( (Name: 'Trunc'; Proc: Trunc_Pas), (Name: 'FastTrunc_SSE2'; Proc: FastTrunc_SSE2), (Name: 'FastTrunc_SSE41'; Proc: FastTrunc_SSE41), (Name: 'SlowTrunc_SSE2'; Proc: SlowTrunc_SSE2) ); begin for var i := 0 to High(FastTruncs) do Spring.Benchmark.Benchmark(BM_FastTrunc, 'FastTrunc').Arg(Int64(@FastTruncs[i].Proc)).ArgName(FastTruncs[i].Name).TimeUnit(kMillisecond); Spring.Benchmark.Benchmark_Main; end.
-
On 3/16/2024 at 5:51 PM, dummzeuch said:If I remember correctly somebody claimed to have improved the jcldebug file format to make it much smaller and lookups faster. Unfortunately I don't remember who it was and where I read about it.
This one maybe: https://blog.synopse.info/?post/2011/04/14/Enhanced-logging-in-SynCommons
-
 1
1
-
-
On 3/15/2024 at 7:14 AM, Der schöne Günther said:In case (for whatever reason), you really just like to add the current line number into a string, then have a look at:
https://stackoverflow.com/q/7214213
On 3/15/2024 at 8:31 AM, Ian Branch said:I had a look at that previously. I may be missreading its use but it seems that JCLDebug relies on an Exception for something like this to work:
The accepted answer to that question doesn't involve exceptions; It redirects the assertion handler to another function which then has access to the unit name and line number.
-
2 minutes ago, William23668 said:Problem solved
No, it's just begun.
Okay, I'll stop now. I think I got my point across 🙂
-
2
-
-
3 minutes ago, William23668 said:They only write to use jcl\install.bat in github
Yeah but have you looked into install.bat (warning: have the suicide prevention hotline on speed dial if you do):
:: compile installer echo. echo =================================================================== echo Compiling JediInstaller... build\dcc32ex.exe %INSTALL_VERBOSE% --runtime-package-rtl --runtime-package-vcl -q -dJCLINSTALL -E..\bin -I..\source\include -U..\source\common;..\source\windows JediInstaller.dpr if ERRORLEVEL 1 goto FailedCompile :: New Delphi versions output "This product doesn't support command line compiling" and then exit with ERRORLEVEL 0 if not exist ..\bin\JediInstaller.exe goto FailedCompile echo. echo =================================================================== echo Launching JCL installer... ::start ..\bin\JediInstaller.exe %* if not exist ..\bin\JCLCmdStarter.exe goto FailStart ..\bin\JCLCmdStarter.exe ..\bin\JediInstaller.exe %* if ERRORLEVEL 1 goto FailStart goto FINI
-
1
-
-
1 hour ago, William23668 said:But when I try to install using jcl\install.bat I got this error:
Include file "source\include\jedi\jedi.inc" not found.
I'm not sure but I think it needs to be installed using some sort of installer which then generates the include file based on something, something, whatever, at this point I gave up and deleted everything.
Delphi 12.1 is available
in Delphi IDE and APIs
Posted
aaaaaaaand it sucks. But at least, from reading the announcement, it appears they know it sucks.