

Anders Melander
-
Content Count
2850 -
Joined
-
Last visited
-
Days Won
155
Posts posted by Anders Melander
-
-
Nope. I just use COM callable .NET wrappers. I would rather have the .NET code live in an external .NET assemble than introduce a dependency on a 3rd party library and have a dependency on .NET.
-
14 hours ago, Vincent Parrett said:TBH, I fell out of love with confluence a long time ago.. we'll probably just switch to some sort of static site generator.
I like it for internal documentation. For external use I think it sucks as you can't style it properly. If we were to replace it I would probably just use WordPress.
14 hours ago, Vincent Parrett said:They announced yesterday they are moving to cloud only and will retire the server/dc products over the next few years - that's just another reason to stop using their products imho.
Oh... wow. I just read their announcement.
For Jira, Confluence and Bitbucket this won't affect us much. Our Jira and Confluence are already on cloud. But for Bamboo this definitely means that we'll have to find alternatives and Bitbucket pipelines isn't a viable alternative. I just took their migration quiz. Bamboo isn't listed at all... and for Bitbucket it recommended that I migrate to Bitbucket Data Center - which is also being EOL'd.. Classic Atlassian.
-
7 hours ago, Lars Fosdal said:Continua has Teams support built in.
Yeah, well Bamboo being an Atlassian product relies on paid 3rd party add-ins for even the simplest things

It does have support for XMPP but that isn't supported by Teams.
-
Nice.
I've been using the following to post the status of our Bamboo build jobs (it's a PowerShell script) but I've been thinking about adding Teams notification to some of our automated test tools and your example will come in handy there.
$uri = 'https://outlook.office.com/webhook/yadayadayada/IncomingWebhook/yadayadayada/yadayadayada-yada-yada-yada-yadayadayada' if("${bamboo_buildFailed}" -eq "true"){ $status = 'Failure' }else { $status = 'Success' } $body = ConvertTo-Json -Depth 4 @{ title = 'FooBar Build Notification' text = "Build of FooBar version ${bamboo.fileVersion} completed with status $status" sections = @( @{ activityTitle = 'FooBar Build' activitySubtitle = '${bamboo.buildKey}' activityText = 'The build of ${bamboo.planRepository.branchName} ${bamboo.planRepository.revision} completed.' activityImage = 'https://pbs.twimg.com/profile_images/1128664840233525248/T3YNFtIt_400x400.png' }, @{ title = 'Details' facts = @( @{ name = 'Branch' value = '${bamboo.planRepository.branchName}' }, @{ name = 'Revision' value = '${bamboo.planRepository.revision}' } ) } ) potentialAction = @(@{ '@context' = 'http://schema.org' '@type' = 'ViewAction' name = 'Click here for details' target = @('${bamboo.buildResultsUrl}') }) } Invoke-RestMethod -uri $uri -Method Post -body $body -ContentType 'application/json'
-
3 hours ago, David Schwartz said:This is another argument in favor of open-sourcing the VCL
It's so easy to throw a statement like that out there. Have you thought about the consequences of having the VCL maintained by a bunch of amat^H^H^H^H enthusiasts that are stuck on Delphi 7? Look at the JVCL if you're in doubt of what that would look like.
If you want open source there's plenty to choose from already.
-
1 hour ago, Ian Branch said:Does anybody know if Alpha Controls supports LMD Tools?
Excellent question... for the AlphaControls forum: https://www.alphaskins.com/forum/
-
4 hours ago, Kas Ob. said:Restart your PC, from the report "system up time : 3 days 17 hours"
Did you work in IT support before you became a developer?

Every time I contact our IT department because there's something wrong with one of the servers, the first thing they ask me is to "restart windows". I've given up on educating them so now I just pretend. My current uptime is 118 days.
5 hours ago, Steve Maughan said:Does anyone know how to fix this?
Try disabling the MadExcept "IDE exception catching". Just to eliminate MadExcept as the cause.
-
 1
1
-
-
Try building with MSBuild (Project Options, Building, Delphi Compiler, Use MSBuild externally to compile). My current client have several projects that fail during compile with internal errors unless we use MSBuild.
1 hour ago, Darian Miller said:Sometimes corrupt .FRM files cause an issue.
Wouldn't that be a linker issue then. This looks like a compiler issue.
-
7 hours ago, David Schwartz said:I'm looking for insights on how to do that.
It sounds more like you're rubber ducking.
-
1 minute ago, Rollo62 said:Wouldn't be the NativeInteger the right cast for a pointer ?
Matching the right bitness on 32- and 64-Bit machines, to the same pointer bitness ?
2 minutes ago, Vandrovnik said:This code is a problem when used in 64-bit version...
Dudes. I'm not stupid.
I'm not saying that it's good practice only that it's safe to cast between pointer and integer. The OP said that this was for 32-bit only so bringing 64-bit into the equation is also irrelevant.
Thanks for playing.
-
25 minutes ago, A.M. Hoornweg said:Result := Integer(TFileStream.Create(Archive.FIIPName, fmCreate))As long as it doesn't do "pointer math" on the integer value then there shouldn't be problems casting between integer and pointer.
-
1
-
-
3 minutes ago, Lars Fosdal said:Would you need to clone that SVG imagelist if you need to use different sizes of icons at the same time?
You don't need to but you can.
It's not really a SVG imagelist. It's an imagelist that also supports SVG meaning it can contain SVG, PNG, BMP, etc. This also mean that you can have one imagelist for low-res containing a mix of SVG and PNG and another for hi-res. I find that PNGs are often better for small (e.g. 16x16) low-res images.
-
 1
1
-
-
48 minutes ago, Dany Marmur said:the DevExpress barmanager/ribbon only accepts one list, this forces med to duplicate icons.
You can only assign one imagelist at a time but if you've named your imagelist according to their instructions then they will switch between the different ones automatically.
If you're using SVG then you only need one imagelist.
-
1 hour ago, Dave Novo said:the crux of the debate is that GUI testing is hard to maintain.
Amen to that.
I've been involved in attempts to implement GUI testing using TestComplete three times in three different companies. Each time the project (the GUI test part) was abandoned after using massive amounts of resources writing and maintaining the test scripts (and by massive I mean several man years). How are one ever going to keep up if it takes a test engineer hours to update the tests for every small UI, workflow or timing change a developer makes. It's much more feasible to write test instructions and have the QA department do the tests manually. They can use TestComplete and the like for simple keyboard/mouse record/playback but the result verification is done manually.
1 hour ago, Dave Novo said:you get failures in things you did not think of.
I remember a place where we outsourced the testing to an Indian company. I was quite impressed by the amount of bugs they initially found with no domain knowledge whatsoever and very little knowledge about how the application was supposed to work. From what I could see from the bug reports they had simply tried pressing every possible key combination or just smashed their hand into the keyboard in every single dialog. They found "features" we didn't even know we had. It made me think of the infinite monkey theorem.
I have yet to see automated GUI test implemented successfully anywhere.
-
Something like this? (untested, just a guess)
interface type TMyFrame = class(TFrame) private FHasLoaded: boolean; protected procedure PaintWindow(DC: HDC); override; procedure DoLoadFrame; end; implementation procedure TMyFrame.PaintWindow(DC: HDC); begin if (not FHasLoaded) then DoLoadFrame; inherited; end; procedure TMyFrame.DoLoadFrame; begin FHasLoaded := True; // Do load stuff here... end;
Of course the frames has to be created before they can be scrolled into view but you can defer loading the frame content.
I would probably solve the problem in a different way but I think the above does what you asked for.
-
1
-
-
16 minutes ago, TurboMagic said:Another possible answer would have been: look at the source Luke!
The first point of entry is the readme. If the readme doesn't convince a potential user then I'm pretty sure they won't bother with the source. We're all busy.
Why should you care? Because more users means more people that are likely to contribute.
-
4
-
-
3 hours ago, Tommi Prami said:FYI: New Approximate algorithm for travelling salesman problem
Woohoo
 Quote
QuoteNow Karlin, Klein and Oveis Gharan have proved that an algorithm devised a decade ago beats Christofides’ 50% factor, though they were only able to subtract 0.2 billionth of a trillionth of a trillionth of a percent.
Oh..,

-
 2
2
-
-
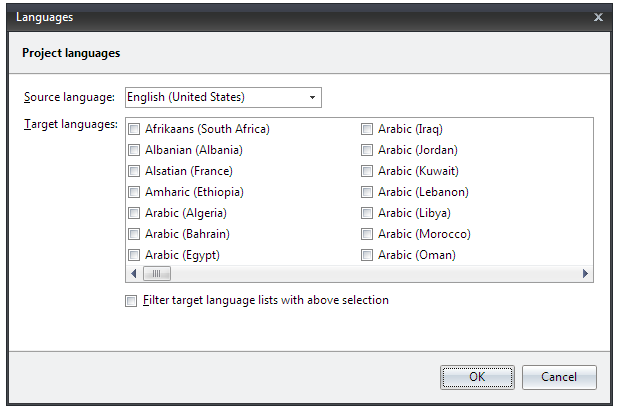
20 minutes ago, lincesmarques said:How to add another language to translate for?
Select the language in the Target combobox.
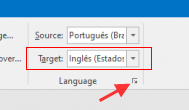
If you click the small button below the combobox you'll get a dialog where you can enable an options that filters the list of available languages:
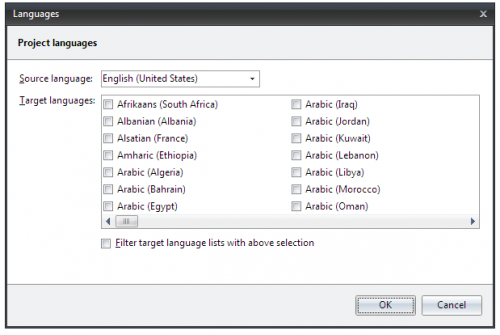
Note that, even though your project can contain translations for multiple languages, you can only edit one language at a time.
-
31 minutes ago, Stefan Glienke said:a generic scan engine - see https://gitlab.com/groups/gitlab-org/-/epics/3260
I doubt most of us would benefit from this feature:
QuoteGeneric SAST engine
What is the type of buyer?
[GitLab Ultimate]QuoteGitLab pricing
Gold/Ultimate: $99/user/month
-
5 minutes ago, Fr0sT.Brutal said:It's a big surprise
After the last 4 years nothing about him surprises me much anymore
-
49 minutes ago, dummzeuch said:I rarely use my smart phone to make calls.
How do you make calls then?
I still have a land line but I haven't had any phones connected to it for ages. I guess I should cancel my subscription one of theses days
 . On the other hand, you never know when it'll come in handy; Zombie apocalypse, Skynet becomes self-aware, Trumps second, third and fourth term...
. On the other hand, you never know when it'll come in handy; Zombie apocalypse, Skynet becomes self-aware, Trumps second, third and fourth term...
-
3 minutes ago, Angus Robertson said:You reach an age where you really don't want to learn new stuff.
And there's even a medical term for it: Rigor Mortis
No but seriously, I'm not that young myself, but once you start not learning new stuff your cognitive abilities will deteriorate: Use it or Lose it.
Your brain will create new neurons your whole life as long as you give it reason to. Luckily the brains plasticity means that a decline is reversible. Just give your brain some exercise.
-
The only general advice I can give is: Convenience or Performance? Pick one.
I won't get into this discussion about which of the many different data types can solve your problem best, because your requirements seems rather fluid and it's impossible to give any targeted advice, when we don't know anything about the specifics.
I'm puzzled why one would even be asking a question like this other than to pass time. If the implementation details are important you shouldn't rely on something someone said on a forum anyway. Try different solutions and benchmark them. If none of the solutions are good enough then there will be something to discuss.
Disclaimer: I've been up all night and I'm on my eight cup of coffee.
-
1 minute ago, pyscripter said:No the performance issue was https://quality.embarcadero.com/browse/RSP-23095 also fixed as suggested.
Yes you're right. That's what I get for thinking I can remember issue numbers while watching a Counter Strike match..
CrystalNet - .Net Runtime Library for Delphi
in Delphi Third-Party
Posted
You can ask @CrystalNet