

A.M. Hoornweg
-
Content Count
494 -
Joined
-
Last visited
-
Days Won
9
Posts posted by A.M. Hoornweg
-
-
1 hour ago, Kas Ob. said:Fine, means are you free to use the first one with extra unused parameter moving the allocating the managed type variable from the the intensively called function in a loop to the caller.
I didn't suggest that you or anyone should use that everywhere, but if you to enhance a loop calling function with such variables then there is a workaround.
I found myself using TStringList very often, it is great tool that can't live without, but when it does come to fast in intensive data processing i found recycling that list yield better performance, as such usage will remove the create and free, leaving me to call clear on exit, which the skipped destructor should called.
Fair enough. You're using the stringlist as an internally shared object, just for saving some time by not having to create/destroy one whenever you need one.
You could take that concept one step further by creating a global stringlist pool (a singleton) from which you can request an available tStringlist whenever you need one. That pool could be shared among many objects and you could even make it threadsafe if you want.
QuoteProcedure tMyobject.DoSomething;
VAR ts:tStringlist;
begin
ts:=StringListPool.GetList;
...
StringListPool.Release(ts);
end;
The problem of having local variables of managed data types such as strings is that Delphi needs to guarantee that no memory leaks occur. So there's always a hidden Try/Finally block in such methods that will "finalize" the managed variables and release any allocated heap space. That takes time to execute, even if there's no further "code" in the method.
-
1 minute ago, Kas Ob. said:just "fields" instead of "local field"
the right wording of the question is
when the last time you saw an object without fields that had been used in multithreading ?
All the time. I am especially fond of classes that have only class methods. They basically act as namespaces.
-
 1
1
-
-
14 minutes ago, Kas Ob. said:when the last time you saw an object without local field that had been used in multithreading
What exactly is a "local field" ?
Do you mean a private field of a class (a member of an instantiated object, located on the heap) , or do you mean a local variable of a procedure or method (located on the stack) ?
-
16 hours ago, Kas Ob. said:move these local managed types vars to be private fields even when each one of them is not used outside one method, here you can recycle them
This makes the object unusable for multi-threading because it is unnecessarily stateful.
-
17 hours ago, Rollo62 said:You could remove the flag, by the use of a PointerVariable as pointer to function.
Would that not potentially incur a cache miss, if the pointer points to a "remote" function?
-
17 hours ago, BruceTTTT said:native client has issues with SQL 2019
Could you please elaborate on that? Anything serious happening?
-
How do you detect if the printer is in use or not? You're accessing one stateful device that's effectively a singleton so the access has to be serialized. If you insist on using threads, you could write a dedicated printer thread.
-
On 10/14/2020 at 8:01 AM, Stefan Glienke said:Use Fixinsight. It catches those.
Thanks for mentioning this, downloading now...
-
tDictionary<T> does manage the lifetime of refcounted objects (interfaces, strings, anonymous methods, ...). If it's in the dictionary, then that's proof that the object is still alive. Try achieving that with "tcomponent.tag!"...
tObjectlist<T> can manage the lifetime of plain vanilla tObject and the user can specify whether he his wishes this behavior or not in the constructor. If yes, no dangling pointers, because the user is not supposed to free manually. Of course the user is not protected from doing silly stuff like still freeing the objects manually. That's life.Yes dictionaries add a few dozen KB to the executable. But hey, RTTI adds a megabyte or so of metadata and for many/most of us it's only dead weight. If there's one single place in the compiler chain where we should be given more control, it's there.
Anyway, I myself have stopped using Tag for pointers to objects because dictionaries made my life much easier. I find myself often using strings as a key because I totally like it when the code tells what it's doing. Tag will only store a fixed pointer, but a dictionary will let me query if an object exists and where it is stored, without any ugly typecasting, in a compact and legible way. 🙂procedure tform1.Button1click(sender:tobject); var callback:tReportShowEvent; begin if ReportDict.TryGet('CurrentReport',callback) then Callback(); end; -
"tag" can fit a simple pointer-sized reference, sure, but you still need to handle ownership of the object. Also, "tag" has no way of knowing if the object it points to is still valid, you may need to clear the tag if the object is freed. That means writing boilerplate code.
TDictionary and tObjectdictionary are "better" because they can handle object ownership. TDictionary<T> can contain managed objects such as strings, interfaces and (I suspect) even anonymous methods. If tDictionary manages the lifetime of the objects, there can't possibly be an invalid association and it reduces boilerplate code.
-
This is what I'm missing in the current version of the type library editor (see attachment): the possibility to use Pascal syntax instead of IDL Syntax. In Delphi 2007 it was still there!
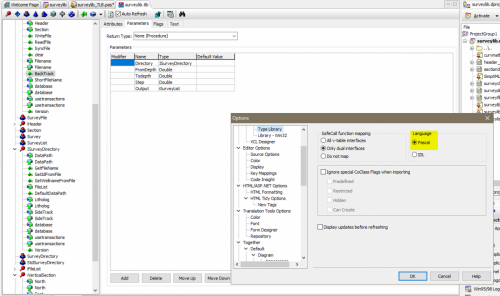
-
Does anybody know in which Delphi version the TLB editor ceased to support Delphi syntax?
-
9 hours ago, Anders Melander said:Make that: In that case your method can be declared "safecall".
Safecall does the same as stdcall returning a hresult and letting no exceptions out. It saves a lot of boilerplate code.
-
You said it is a COM server. In that case your method has to be declared "safecall".
Function tmyclass.method1:Olevariant; Safecall;
That basically does the same as returning the Olevariant as an OUT parameter but in the background it additionally returns an integer (hresult) which tells the caller if the call was successful or not.
[Edit] I just see you use the type library editor.
Since a couple of years Delphi's type library editor no longer works with Delphi syntax directly, unfortunately, but only with RIDL syntax which looks a bit like C. Here you can see that the function's result is a HResult and the Olevariant is an OUT parameter. You will also see that the automatically created Delphi interface has functions using the "safecall" calling convention.
Older versions of Delphi had a type library editor that could work in Delphi syntax directly, I found that much more straightforward to use.
-
1 hour ago, Remy Lebeau said:That is not possible. Delphi is a compiled language, you can't alter object layouts at runtime. The best you could do is store your data in another class/record object that you create at runtime, and then use the component's Tag property to point at that object.
Please don't misuse "tag" for pointers.
I'd rather use a tDictionary<tcomponent, tSomethingelse> to store associations between components and objects. It's much more universal and transparent.
-
2
-
 1
1
-
-
17 hours ago, David Heffernan said:Packages do work. If you can't make them work in your setting, that's probably more a statement about the constraints that you are imposing.
That may very well be so. But in my particular constellation they do not work and I'm not going to try again.
Edit:
Let me illustrate one of the many many problems I stumbled upon.
Assume you develop some COM DLLs and some applications as independent projects and you wish to compile everything with packages, just for the sake of saving footprint. Also assume that some of these DLLs have visual dialogs, using third-party components (LMD, TMS etcetera).
The unintentional side effect of this constellation is that the DLLs and the application share global variables in memory, such as the "Application" object.
Without packages that would not be the case. If any DLL manipulates events of tApplication in its initialization process, such as setting "Application.OnMessage:=SomeMethod", that is a protection fault waiting to happen, because as soon as the DLL is unloaded from memory by the operating system that event will point to an invalid memory location whilst tApplication is still "live". And a lot of third-party visual component libraries do this unfortunately. In my case, the DLL's are COM dll's and the operating system loads/unloads them dynamically.
-
18 minutes ago, David Heffernan said:Using packages would achieve that
Packages don't work in this constellation. No really, they don't.
-
1 minute ago, David Heffernan said:If you really want to reduce the size of what you deploy then use runtime packages instead of DLLs and you won't duplicate RTL/VCL classes. Likely that would save you far more than you would save by stripping RTTI in the RTL/VCL code that you link, were it even possible for you to do that.
Packages aren't possible in this project unfortunately. I've tried it but there were too many issues.
For the time being I still deploy using Delphi XE, using a recompiled version of the RTL and VCL that has most of the RTTI stripped out. But soon I must move everything over to Delphi 10.4 Sydney and I'd really like to find a way to reduce binary size.
-
28 minutes ago, David Heffernan said:Why would it be duplicated? Why would the same RTTI be found in different DLLs?
Why are you singling out the RTTI here? Isn't the fundamental issue that you have duplicated code. If the duplication of the code bothers you, don't have duplicated code. And guess what. You then won't have duplicated RTTI.
Or am I missing something?
Of course there's duplicated code, the whole sense of libraries is that they contain stuff meant to be re-used. I bet that every DLL of mine carries tStringlist, tButton and a thousand common objects more. It's not the duplication of code that bothers me, it's the big block of non-code I didn't ask for.
-
47 minutes ago, David Heffernan said:Why does it make a difference whether or not the code is in a DLL?
I'm not talking about "a" DLL. I have a project consisting of lots and lots of (com) DLL's that are used by several other projects in our company. These DLL's have many code libraries in common. The problem is that the RTTI of those libraries gets linked into every one of them. It adds up. And since I don't use RTTI at all, it's a dead weight multiplied over and over again.
I must deploy my software to oil rigs in remote locations and the connections are most often slow and metered, so the bloat is very undesirable.
-
20 hours ago, David Heffernan said:I don't think RTTI doubles or triples the size of your executables. I also think that people worry overly about the size of the executables. Certainly worry about this on mobile platforms, but generally on desktop platforms you should be less concerned of the increases due to RTTI.
In projects consisting of numerous DLLs it is a pain though. I wish I could strip it out completely in those projects.
-
Thank you very much!
-
@Anders Melander that would be very kind of you! I'd like to take a closer look at it at the very least !
-
@Anders MelanderThis recording application stores processed data records at 10 Hz, which is slow by any metric, but it performs sampling and aggregation at a much higher frequency. This is a "finished" application, tried and tested, and we'd like to avoid breaking anything because its reliability is vital to our business.
But since the beginning of the Covid 19 pandemic my entire department works from home and we have the need to access that data. So the idea was to make a tiny modification to that application, to give it a circular buffer in RAM that is accessible from an outside process and to dimension that buffer big enough to contain an hour of data.
We would then write an independent application that acts as a TCP server, allowing us to stream large chunks of data from the buffer. Not disturbing the data acquisition itself is an absolute necessity, hence my question about a lean locking mechanism. It is absolutely no problem if the consumer must wait a few ms, but the producer should be as undisturbed as possible.
And of course I meant the word "pointer" in a generic sense, not as a logical address. The buffer would get a 4 kb header with a version number and some properly aligned control variables. All "pointers" in there will just be record numbers.
Micro optimization - effect of defined and not used local variables
in Algorithms, Data Structures and Class Design
Posted
Especially tricky to optimize are hidden managed variables. Delphi creates those when it needs to store intermediate results of managed types [as in tstringlist.add (format('Test %d',[123]))].
It would be great if there were developer tools that would point out the creation of such hidden variables.