

David Schwartz
-
Content Count
1264 -
Joined
-
Last visited
-
Days Won
26
Posts posted by David Schwartz
-
-
Boy, this terminology is making mincemeat of the discussion....
We have 850+ project folders that are used to build standalone EXEs for parsing unique input data formats and turning them into something similar to PDFs. The original developers could just as easily have chosen to make them DLLs since they all have the exact same "footprint". They're all for "clients" of one kind or another. All 850+ of them. Our routine work involves very little with Delphi, however. I may need to change a logo, or a return / remit address, or a monthly greeting on a statement. There's virtually no programming involved, although they call us "programmers".
I suspect they see the value of having Delphi experts on hand is exemplified by a request I got today: we have a data file that aborts; after looking closely at the data, I can't find anything unusual. Please spend some time stepping through the code and let us know what the problem is." Such fun.
Back to git ... personally speaking, I think the repos should be set up on a per-project / import EXE / folder basis. That way there would be no interference with other projects when it comes to managing the stuff we do on a day-to-day basis.
-
8 hours ago, Anders Melander said:I can't see anything in what you describe that is out of the ordinary. Looks like a pretty standard workflow to me.
I've never really seen any discussions about this kind of a workflow in git, and it's very different from anything I've been around before. A couple of the others at work find it very unusual as well. But if it's familiar to you, then you can probably help.
8 hours ago, Anders Melander said:One thing I would do is make sure that very few people have rights to push to Master or whatever you call your primary branch. Instead use pull requests to merge into Master. This avoids the situation where someone forces a push and rewrite history and then later claim that "git must have messed something up".
This is exactly what we're running into. Not just me, but others.
I don't understand what's meant by "use pull requests to merge into Master". I see people on GitHub say that if someone wants to make changes, ask for a pull request. Anybody can download files and change them. I don't get why you ask for a pull request when you basically want to "push" stuff up to the repo.
I did do something in master after making some changes in a branch, and effed everything up. I think I collapsed origin onto master with a "git pull origin master" from master when I thought I was in a branch.
I think in pictures, and I've never seen any good illustrations about what goes on when you're working in git. Everything is text. I just haven't had that "aha!" moment yet where I can visualize what's going on in my head. It seems to be like you're interviewing yourself. You start out in one chair, do some stuff, switch seats, talk for a while, switch to the other seat and process what you said earlier, then say some stuff, go back to the other seat and process that, and so on.
8 hours ago, Anders Melander said:I'm not sure what to do about your I: drive if you really want to have all the files there at all time, regardless of the branch you're working on. If you're okay with pulling the files for a given branch to I: when you work on that branch, then you could reference you I: repository as a submodule in your main Git project. Then each customer could get their own branch in the I: repository.
Nobody likes that we do work in one folder and git is constantly shuffling around files in other folders, and throwing up conflicts because someone else is in the middle of doing some work that has nothing to do with what you're working on. Branches only seem to make things worse. When I do a branch, I only want to focus on a given folder. What happens is we pull along a ton of other unrelated crap, and if someone happens to push an update to any of it while we're working, it can cause a conflict with stuff we didn't touch.
I'm trying to figure out if we could reorganize things so that each client (reseller) has their own repo and folders beneath them for each of their customers, rather than at the I:\ root. So we'd go into a folder and then create a ticket there and it would only affect that repo. I don't know what would happen if we switch to another folder / repo and work on a ticket there.
Honestly, having a file system with no history and a history manager that fiddles with the file system is quite confusing to me because it leaves it up to you to remember to tell the history manager that you moved somewhere else in the file system or the history manager gets totally confused.
-
On 9/2/2020 at 12:10 AM, Lars Fosdal said:If I take the liberty of making some assumptions about these states
This is a nice idea for a summary dashboard, for sure. But in this case, I'm looking for something that only applies to individual tickets. It's a tool to help both show the person what's needed as well as signify what's done and what's left, sort of like a check-list.
-
On 9/2/2020 at 4:01 AM, Stefan Glienke said:Sounds more like current git workflow is done wrong when there is a struggle with 3 people trying to use it - because git was exactly invented for a distributed team (linux kernel).
Yes, that's our thinking exactly. Which is why I'm looking for some input from others about this. I'm not very fluent with git myself; mostly it confuses me.
-
Ok, well, I posted the issue in a separate thread if anybody wants to look at it. It's a "real world" scenario, not something over-simplified as a class exercise. Maybe I provided too much info, but I tend to try explaining all relevant aspects rather than just one piece and wait for people to ask about other sides of the issue.
-
Well, let me try asking this here and see if anybody has any suggestions. It's about our workflow. It's probably more info than is needed, but it gives a broad overview of what we're dealing with.
I know that git itself is neutral as far as workflows go. Someone published a guide called "gitflow" that is designed for a workflow followed by typical software development organizations. That fits for the last few places I've worked, but it does not fit the organization I'm currently with at all, nor any of the similar models targeting that kind of environment.
Unlike gitflow, we do not have a team of people working on a core set of code that evolves over months and months. We have a few people, sometimes just one person, working on a constant stream of very small, independent quick-turnaround requests that get updated and pushed into production in a matter of hours or days.
THE BUSINESS MODEL
If you're interested, here's the business model: This is a business that started out to do high-volume printing of bills, statements, and invoices, and got pulled in a different direction by every client they got. On the surface, it's a simple mail-merge process. In practice, it's a nightmare. Every client submits data to us in a different format. Most of our "clients" are resellers, like a property management company that manages apartment complexes, or condos, or rental properties. Apartments here send out two or three things a month: an invoice for rent, a statement for water and maybe trash, and some send out a newsletter. The management company uses the same templates for all of the properties they manage, but they'll each have different names, logos and return / remit addresses. So they send us a file with account data and whatnot and we have to consolidate that into a page-by-page printable stream that's sent to what amounts to a huge laser printer. It starts with a 5' roll of 18" wide paper at one end, and spits out USPS trays of sealed envelopes (pre-sorted by zip code) that contain folded materials with whatever else is needed, often with inserts like return envelopes and other kinds of coupons. The same thing everybody gets from their utility companies, gas company, water folks, department stores, etc. No two are alike.
That's what the business DOES.
THE WORK
As far as the work goes, it's a little hard to describe. They SAY it's "programming" but I don't really know what to call it. It's mostly clerical work IMO. Aside from new account setups, eg, a property mgt company brings on a new client of theirs, most of our work consists of changing logos, return / remit addresses, and verbiage on statements -- like "here's what we want in the message box for September's statements: _____" kind of stuff.
Back around 2004, a team built this rather convoluted framework in Delphi that handles every aspect of this business. It has been running very nicely since then. An investment company came along in 2012 or so and bought the existing company and most of the developers left. Nothing much has changed since then.
The core of all our work is the data import process. As I said, every one of our clients use a different format, although the data for individual accounts from the same client / management company is pretty much the same since it all comes from the same management company.
The import process for each account is handled by a Delphi app that runs by an automation process. One of these lives in a folder designated for either a single account (eg., property) or group of accounts managed by the same client.
We get requests almost every month to tweak the bills. In a perfect world, we'd bring up a WYSIWYG tool that looks like Word, make a few changes, and save it. We're far from that.
Changes to data displayed on printed materials can occur in a half-dozen different places, some static, some dynamic, some in-between.
Input files are in a variety of formats: XLS, TXT, PDFs (that we scrape or use OCR to read), and lots of indescribable proprietary formats. The import apps are in Delphi. The intermediate files are mostly PDFs. The page markup language is TeX.
When we get a request in, our first task is to figure out which file or files needs to be modified. We make the changes, do some testing, then finally create a "proof" (a PDF file) with some test data from the client to show them the results. When they say it's OK, then we "push it into production". From start to finish, it can take 10 minutes to several hours to do the work needed to process a single change request. Frequently this work spans several days due to questions or issues that come up. Once work is done and we send a proof out, it can take hours to days to get approval back. We don't push anything into production until we get approval.
We use git to track all of the changes in our files. Our work is focused on "tickets" where we need to make the changes requested in a given ticket. So we set up a branch in git to capture file changes for each ticket.
We can alternate work on different tickets throughout the day. We can put work on a given ticket "on hold" for a day or more.
It's rare that we can work on a ticket and get it approved by a client and pushed into production the same day, but it happens. It's usually the approval process that causes the greatest delays.
Larger clients will submit tickets for several different accounts the same day, and they can be handled by different people in parallel. Their data is all in the same folder, so we're all working with different data, but sometimes it's in common files. Many clients keep a list of accounts in a single CSV file, for example, that our software reads to get static data for a given account number. This acts as a very simple database. Obviously, it needs to be updated in Excel or a special editing tool someone made for us to use.
Some of these files eg., common CSV files, some template files, etc.) are pushed into production b/c they're read at run-time. Actual "source code" files are either compiled or generated on-the-fly so are not pushed into production. Either way, they need to be captured by git.
Everybody works on a local copy of the data that resides on our own computer. We rely on git to handle merges and merge conflicts.
The problem is that from time to time, get gets confused. We recently found something pushed into production where the file that was changed had been reverted to the previous version of the file. Somehow git messed things up. Git showed the previous version as "current" and it replaced the modified version that was actually newer.
In another case, a guy went through a common client file and commented out about 1/3 of the lines in the file, saved it, and pushed it into git. Two weeks later, we discovered everybody had the unedited version on our local stores that git decided was "current" and we were changing and pushing into the repo. We don't know how that happened, but it caused problems.
In summary, we have lots of quick-turnaround work that's done for individual accounts. Some common files can be changed by the same or different people actively working on different tickets.
We can also have multiple tickets in the same folder that we work on the same day that are for different accounts but touch one or two of the same common files, so we need to switch branches between tickets to ensure we only capture changes made for individual tickets.
I should also mention that we have a couple of folder trees mapped to local drives that we use to isolate things for git purposes. All of the folders in which we keep files for client accounts are contained in the I: drive. It has a .git file in its root so everything we do applies to the whole drive / folder tree. This is quite annoying at times b/c a lot of files show up as changed that we never touched, are not interested in for a given ticket, and are often forced to deal with for conflicts before we can work on our tickets that are totally unrelated.It would be really great if we could get git to let us focus only on a specific folder and ignore everything else on the drive. I don't mind conflicts, but let me deal with them when I'm working on a ticket related to those files, not something totally unrelated.
-
I'd have a list of unprocessed requests that feed the sending agent. If the agent dies, the list sticks around.
The challenging part is the potentially diverse time dynamics involved.
You could use a multi-threaded design to feed hundreds of messages per minute to an API for a commercial SMTP service, like SendGrid, or just use a simple loop that sleeps for sending to a shared hosting account that limits you to 100 per hour or 500 per day. If you try sending through your ISP, like your cable company, you risk getting shut down if you exceed certain limits that they don't like to disclose.
Sending stuff through an SMTP relay is, on the surface, one of the simplest things you can do. But the practical implications of it -- being that it's probably the single most widely abused resource in the entire internet world -- are that your sending agent needs to be highly resilient and pay close attention to the error codes it's getting. It needs to be programmed like that song about The Gambler -- know when to hold 'em, know when to fold 'em, know when to walk away, know when to run... You do not want your SMTP host to shut you down, especially when it's your ISP or web host b/c they could just as easily shut down your entire frigging account!
That's a really big benefit of using a 3rd-party SMTP host -- the worst they'll do is shut of your SMTP account. And it's easy to find another one. (Better yet, set up several before you even get started.)
-
5 minutes ago, Bill Meyer said:But data drives the presentation*. If you are a DevExpress licensee
in this case, we know its hierarchical. But there are probably dozens of ways to display and navigate a hierarchy. 🙂
* vertical (trees), horizontal (org charts), or free-form (mind-maps)
* bubbles, boxes, graphics, text, both
* lines or not
* static or dynamically expandable/collapsible
* background colors / graphics / highlights
* editable (inline, popup, separate form) or not (configurable vs. hard-coded)
For what I described, I'm curious what comes to mind most naturally. I rather doubt something like a mind-map would flash up immediately.
We don't have either DevExpress or TMS, unfortunately. They've got some stuff that would be great for what I'm building here.
-
I'm kind of limited on vertical space.
What about a combo-box with the main items, and that displays a different list of check-boxes below.
Maybe when you click the down-arrow on the combo, it shows the list of radio items. Pick one and it shows that item in the combo as the one you're working on and the check-boxes below.
Or start with the radio buttons; pick one and it disappears but shows the selected item at the top with its related check-boxes below. Kind of a "drill-down" effect.
Do you think you would you find something along this line easy to use as well as compact?
Thoughts?
-
1 hour ago, Bill Meyer said:If your processes are stored in a table, and the steps in each are contained in delimited text in the process record, then you could stay with the radio button -- or checkbox -- group model, but easily customize per process.
Alternately, you could use master/detail tables to contain the processes and their steps. As to the UI, a TreeList could also be a good approach.
Ahh, this is what I was trying to avoid -- storage details. 🙂 Forget what's under the hood. What does it LOOK LIKE?
A treelist is sort of my automatic go-to choice for the UI. What I'm looking for is ... something different. I'm curious what others might come up with.
-
There's clearly a hierarchy. I'm mostly curious how folks would handle it, which is why I didn't bring it up. (My mind seems to be locked-in on a tree-view, so I'm looking for some other ideas.)
I'm guessing you'd start with what I showed (the main tasks) and then when one of those items is clicked you'd show this in a popup?
Then once all of the required sub-steps is complete then the parent would show complete?
I had not thought of this. Thanks! -
I've had very poor luck getting general questions like this answered on SO. They usually get downvoted and then locked.
I'm thinking more like git-specific forums that help folks understand git better. It's an open-source project; aside from discussion boards about specific tools, all I can think of is the tool vendors.
This is a forum about Delphi. It's not run by the vendor, but by people who are engaged with this product.
Are there any similar forums on git?
-
19 minutes ago, aehimself said:People usually pay because they need GUARANTEE. What happens if your house and your friends house catches fire at the same time?
No matter what solution can be put forth, you can always come up with a scenario that invalidates it.
That only leaves you stuck where you are with very little interest in anything. It's the ultimate demotivator.
Apple started out as a hobby. Only instead of listening to Woz' arguments about why nobody would by even 10 of his 6502-based home-brew computer boards, Jobs said, "Let's build 100 of them!"
I'm not interested in all the reasons you can find not to embrace anything at all. I have stuff stored in my garage that by all accounts should be totally unreadable today. You know what? Everything I've tried to read that wasn't so brittle that it shattered ... worked fine. It'll outlive me. But according to your view of the world, none of it would be here because all the "experts" say it would not survive this long.
These "experts" base their opinions on statistical data based on accelerated environmental testing with known limitations.
Once I had a contract to help some guys show how so-called commercial off-the-shelf (COTS) hardware fared against similar mil-spec equipment that cost 3 orders of magnitude more for the same (or worse) functionality. The guys doing the testing put both sets of hardware through the most severe shake-and-bake testing they had, and the fully-ruggedized mil-spec hardware had a 50% greater failure rate than the COTS hardware.
So I don't put a lot of stock in what statisticians say when it comes to the longevity of electronic components. The stuff tends to fail early within 90 days; or it starts dying at around it's projected MTBF. But fully half of it will last 3-5x it's rated MTBF. That's statistics for you.
Of course, you can always pull out that Joker card and argue that no matter what the MTBF is, there's always a scenario they didn't account for that will kill it off immediately.
And don't forget that a meteor could fall out of the sky and kill you right where you are ... any time of the day or night, wherever you are on the planet. Even if you're driving down the road, flying, or whatever you're doing.
You could also spontaneously combust.
-
16 minutes ago, Attila Kovacs said:Me too. Also funny one. Especially that you don't understand why would one use an online service to make a complementary/secondary cold-backup in a different geographical location, then you answer your own question in 2 minutes with the burglars.
You obviously haven't had cloud services you subscribed to that were supposedly "secure" and said to be on solid financial footing, go belly up one night.
I have.
Nor have you had servers you were paying to be "secured" get raided by law enforcement just because they were co-located near someone who they were investigating for criminal activity and so they were able to get search warrants for every machine inside the "secured" area -- as if all of that equipment was owned and/or operated by the crooks they were after. They seized ALL of the equipment in that "secured" area and hauled it all away. For weeks.
I have.
But burglars ... they don't know much about tech. They go after TVs, stereos, microwaves, and stuff that looks familiar to them. Things they see at Best Buy with big price tags on them. If you have specific valuables in the house, and they know they're there, they'll head for them. If you're gone for a while and they can spend the time to toss your entire place, then a safe isn't going to be very "safe". But things that look like cable boxes and modems that can be bought at Goodwill for $5 aren't worth their time.
They'll steal a Bluetooth speaker worth $50 and not even think twice about your $10,000 Marantz 6-tube stereo amp and FM receiver that look like something their grandparents used.
If you had one of those big old computer tape drives in a rack that was spinning and had lots of blinking lights, they'd take that before much else.
Sometimes "security" is more about "playing the odds" than building a better Cheyenne Mountain.
-
1 minute ago, Anders Melander said:A small fireproof safe isn't that expensive. 400 EUD will get you started and I'm sure they can be had for a fraction of that second hand.
I see this as a rather silly discussion. The chance of being burglarized is far higher than having your entire house burned to the ground.
Safes are used to contain valuables. Fireproof safes are perceived as containing really HIGH-VALUE things (like wads of cash). So thieves might be more inclined to grab a safe than a nondescript box on a wall in the back of a closet with a bunch of random wires coming out of it. For all they know, it's from the cable company and is useless if stolen. Maybe put some verbiage to that effect on it to throw them off...
Don't forget that it's going to be pretty useless if a burglar can pick up your fireproof safe and walk off with it. So add in some way to secure it sufficiently that it can't be carried off. Keep in mind there are folks who actually steal entire ATMs to crack into later and extract the funds in them.
-
42 minutes ago, aehimself said:...which would immediately make it a non-ideal backup solution.
It's an IDEA. Like scrambling eggs ... some people put milk or creme in them, and for those who are allergic to dairy products, well, that's a non-starter for them. That doesn't mean that they cannot eat scrambled eggs, just not with dairy in them.
You don't have to keep telling us here that you're allergic to anything but mag tapes. We get it. It's getting old, and you're free to use whatever kind of tape backup unit you want in place of whatever other storage is suggested. But replacing it with cloud storage kind of negates the whole idea, so don't bother to go there.
BTW, why is it that so many people who are allergic to paying anything for software seem to have no problem paying for cloud storage when they can roll their own using an old computer, whatever storage medium they prefer, and free software?
I mean, that's basically what I'm suggesting here -- save yourself $100/yr in cloud storage fees by using free stuff and things you're already paying for. Dropbox charges $10/mo or $100/yr for 2TB of cloud storage. So build a couple of boxes with 2TB of storage; set one up at your home and the other up at a friend's house, and have the remote one mirror the local one. Problem solved. And if your cloud vendor suddenly shuts down or gets raided or hackers suck all of the data out of it and expose your secrets ... well ... where does that leave you?
-
I'm looking for design ideas in terms of how to approach this process model from a UI perspective. This isn't something that gets discussed very much here, so I thought it would be fun to see what others have to say.
FWIW, this is something I'm building to save my own sanity at work. 🙂
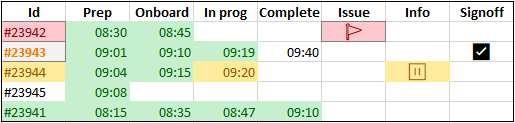
Say you have a process that has several steps, eg:
o Prepared
o On-boarded
o In Progress
o On hold / problem / issue
o Waiting for more info
o Pending signoff
o Completed
I set these up using a TRadioGroup. It works ok, but I'm finding things "falling between the cracks".
So I'd like to break each one into more detailed steps. If there are sub-steps, each of the sub-steps must be checked-off in order to get the entire step marked as complete. Some can be optional, but the required ones need to be checked or some alert will be displayed.
The nature of things is you can't really jump ahead, but you can go back -- mainly to the hold or waiting steps then back to "In Progress"
"Pending signoff" might breakdown into these sub-steps:
-- Team code review (optional)
-- Team signoff
-- Publish to QA server
-- QA tests complete
-- QA signoff
FWIW, this is not intended to implement a fancy and highly-controlled workflow of any kind. Rather, it's intended to be more of a GUIDE ... a list of things to remind us of all the detailed things that need to be done for different kinds of tasks, like a checklist.
There's a similar approach to each task, but they have some variations depending on different things, and it's often hard for us to keep the differences straight. So having a list that's customized for a related set of tasks (or task group) will help us keep from doing stuff that's not needed, or forgetting things that are needed, for each kind of task.
For example, one group of tasks might require you to paint things green, while another might require them to be painted white. They all require being painted, but having a specific thing that says what color for a given group is often very helpful, so you don't have to ask someone or go searching through your notes. It's not obvious if you don't know, and not well documented otherwise. Until you've done it a few times, that bit of missing data can slow you down quite a bit. So rather than simply saying, "Apply paint" the step would say "Apply GREEN paint" or "Apply WHITE paint" or whatever, depending on which task group it belongs to. That's what I'm trying to get at here.
For any given group of related tasks, their lists would be pretty much static -- that is, the steps involved change very rarely. (They've been in place for years. The problem is, one guy has been doing them for years, and he has forgotten more than he can recall. In training us to do this stuff, he's missing lots of little details, and we're having a hard time documenting this in a way that makes it obvious at the time we need to know.)
Timing wise, a lot of these tasks can be handled in an hour or two, most within a single workday. Sometimes they end up spanning several days, especially when they get put on hold while we wait for clarification of ambiguous or missing details.
This would also make it easier to bring on new people.
How might you approach this from a UI design standpoint? (I don't expect to see a single component that does it all, but who knows?)
(I'm not looking for how to store this data in records or lists ... but how to represent it visually on the screen using VCL components.)
-
21 minutes ago, aehimself said:Proper backup solutions require the backup area (including servers and libraries) to be physically separated to different buildings. Thus, production center burns - you still have backups and vice versa.
I also run a machine with extremely low power consumption kilometers away from my house. It's only job is to replicate the data from my prod server, when network is up.
it occurs to me that it wouldn't be hard to find a friend with internet access where you both set up a small backup server, like a Raspberry Pi 4 with some SSD on it, and physically placed them at each other's homes instead of your own. Or maybe set them up in pairs so you have one at home and one at their house, and the remote one mirrors the local one.
-
I'm looking for some help with our particular usage model, not individual commands.
It seems it has been working fine with one guy and a part-time assistant when they could coordinate things, but with three people now working in parallel, it's got us all tied in knots.
I suspect most folks here are mainly using git alone. This is a small but growing virtual team of devs we've got and most of them are familiar with TFS. Git has them scratching their heads. And our production schedule / model is not what something like gitflow was designed for.
I'm wondering if anybody here knows of any public discussion groups (of whatever kind) that focus on this kind of topic?
-
You don't HAVE TO generate an exception.
Maybe you're talking about what most error loggers are used for.
You could also use something like MadExcept that would trap the exceptions and log them for you automatically, send an email, and suppress the exception alerts if you want -- which is useful if you can't modify the source code.
-
9 hours ago, Anders Melander said:So you're good with relying on the cheapest available devices to save you when your primary storage fails? Interesting.
Personally I would prefer a reliable backup medium so that I could afford to use faster, but less reliable, primary storage devices.
Well, I guess it's a matter of perspective. OGs like me who still have boxes of 3-1/2" floppies stashed away remember using them to set up rotations for backups. Sure, they failed, which is why we set them up in batched rotations! Ditto with tapes.
I was looking around for some backups of work I did at one point back in the early 90's. It was between the "floppy-disk era" and the "writable CDs era" when I used one of them "super-high density and high-reliability" tape drives. Now I've got a few years of backup tapes with stuff on them and no way in the world to read them. I can still read those old DOS floppies and the CDs. But backup tapes? <shrug>
Whatever you might think of SDs, I guarantee they won't decompose the way old magnetic media does over time. There's not much room to write on them, to be sure, and with them getting so cavernous that it'll be impossible to use them for long-term storage without taping them to a large printout that says what's there. But I don't know anybody who does that the way we used to mark-up floppies. Besides, you really couldn't put much on floppies, so it wasn't that big of a deal. CDs started to become a problem in that respect.
As for online backups ... there seem to be three options: smaller free accounts that piggy-back on larger subscription models (like Dropbox offers); monthly subscription offers, which tells me the company will probably be around; and single-payment "lifetime" offers, which will eventually disappear for lack of revenue. I've already been bitten by one of them that shut down 6 months after a huge surge of initial customers. You've gotta have a way to keep the lights on, if nothing else; people forget about that. The problem with the monthly subscription deals is ... when you stop paying, everything will evaporate (sooner or later).
I'll trust a box filled with ANY kind of media, including SDs, far longer than ANY online service after I stop paying their bills. SDs _are_ a very cost-effective one-time payment for a huge amount of storage, and you're in 100% control of them forever, unlike 3rd-party cloud storage where you really have no idea how it's being used or even of it will be there when you need it. Consider how much storage a bunch of microSDs could hold laid out to cover the same surface area as one writable CD/DVD. A CD is 700MB; a DVD is 4 or 8 GB. I'm guessing that 1TB microSDs laid out to cover the same surface area as a CD would probably yield 50 TB or more of storage. I don't know who'd need that much on a regular basis, but using, say, 60 x 1TB microSDs for a rotating backup would mean you write each one a total of 6 times per year if you make a daily backup of ALL your data and it doesn't exceed 1TB.
Anyway, unless you're creating or editing videos and large graphics files (or humongous databases) on a daily basis, only a very tiny percentage of your data changes day-to-day. So most of the data you capture with full backups from one day to the next will be >99% redundant and remain static going forward. The likelihood of "losing" stuff is going to be more depending on your ability to actually FIND IT rather than physical data loss. So there's a great market gap opportunity: a search tool that lets you index your backup media and keep it independent of the media so you can search for stuff "offline" as it were. -
34 minutes ago, haentschman said:Is this what you mean? ...the base folder for new projects?
Yup, that would be it. And if that SSD drive dies before you do for some reason, you can change it to have Delphi look somewhere else.
-
14 hours ago, aehimself said:Having a completely separate import application for each "client" seems to be a huge waste of resources. .
This system was designed in the 2004-2008 timeframe by people who are long gone. It's a legacy project that nobody dares fiddle with. It has been running day-in and day-out for 15 years and the overall system is quite stable and robust. Resources are not anything anybody cares much about, and cutting them by 25%-50% yields no useful ROI. Reliability is paramount.
I'd love to redesign and rebuild this from the ground-up, but management here is of the same opinion I've encountered everywhere else I've worked since 2007 -- if they're going to rebuild it, it won't be in Delphi. The ones who DID undertake rebuilds under .NET ran WAY over budget and schedule, and the resulting systems were big, fat, slow, and unreliable. Meanwhile, the Delphi-based software just kept chugging along, solid as a rock and reliable as ever.
Most places do not want to replace legacy Delphi apps because they're so solid and reliable. But they don't give that much consideration when it comes to new product development.
The only work for old Delphi hacks seems to be working on maintaining old legacy systems. I'd love to find a new major project being developed in Delphi, but I haven't heard of any (in the USA anyway) in years.
-
12 hours ago, aehimself said:P.s.: I'm not considering any flash-based (including SSDs) devices suitable for backup. Their write cycles are low
For average use as a backup drive (as opposed to replacing your HDD in your main computer that you use daily) the MTBF would be around 100 years. Spinning HDDs are <5 yrs, esp. if they're in a NAS that runs continuously. Flash storage doesn't "spin" and really don't do anything if they're not being accessed, unless your hardware logic is constantly reorganizing them and running tests, which seems silly for SSDs.
Personally speaking, I've found most traditional HDDs fail after about 3 years. I have SSDs in my 2014 Mac Book Pro and they're still going strong. I put them in my 2014 Mac Mini that I use daily and so far no problems.
My last 3 employers over 10 years had SSDs in our work laptops that we used regularly. I never had any trouble, but a colleague at one place had his SSD fail after just 3 months of use. The IT guy who fixed it said it was only the 2nd failure he'd seen since they started using them a few years earlier, and this one happened to be brand spanking new. It was a Dell laptop.
Honestly, the price of SD cards is getting so low that you could make rotating backups just from a handful of them. I see Walmart is advertising 64GB Class 10 microSDs for $5. I see an outfit named Wish.com that's selling 1TB Class 10 UHS-1 TF microSDs for $7.64. SD cards aren't nearly the speed of an SSD like Samsung T5's but for backing up source files on a daily basis I don't think the speed differences would even be noticeable. If you got 10 of them and rotated them daily, you'd use each one 36 times a year. For devices rated in the 7-figures, I wouldn't be terribly worried about long-term reliability at that rate. You'll be dead and gone by the time one failed.
git workflow question
in General Help
Posted
I think you're thinking we spend months working on stuff. Our work is very quick turnaround -- sometimes less than an hour. We can be faced with git conflicts several times a day. I've spent more time "resolving" conflicts on code I had no hand in than it took me to do my ticket. It's a serious distraction.