

mael
-
Content Count
29 -
Joined
-
Last visited
-
Days Won
2
Posts posted by mael
-
-
For S-Records/Intel Hex the gaps are explicit, like in every program that supports these formats.
It's not really related to structure parsing or presentation.
HSD currently assumes 1 byte packing and no padding, but I will add options later to explicitly state alignment/packing/padding using type parameters, such as
StructName<Param1=Value1, Param2=Value2, ...>
This is similar to how pointers work now. See earlier posts with pointer<AddressType, SomeTargetType>.
-
I was looking for feedback on the syntax maybe. And I have seen a lot of formats, most of which are not fully declarative, and one of a thesis which is rather complete, but which isn't open source/fully explained.
Honestly, the exchange is part of the motivation. But probably I have more freedom that way.
Regarding S-Records, yes they are supported, import and export. Support for gaps is added in the soon to be released version 2.5.
-
On 2/1/2021 at 10:55 PM, David Champion said:@mael looks like you are well into the task and really motivated.
You explain it very clearly but I will need to re-read the comments in the morning, since I have been
working long hours and am just finishing for the day.
I'm catching your excitment.
Were you planning to comment anything further, or just intended to look?
-
@David Champion Thanks, this is a summary of the work I have been doing over a longer period, more work is needed. I edited the posts a bit and clarified them, so rereading them later makes sense 🙂
-
Later I added the ability to define pointers which automatically use a function to map addresses, with this syntax:
PVirtualAddress = pointer<UInt32, UInt32, RVAToFilePointer>
The first UInt32 defines the address size (this is settable, since you cannot assume all pointers in a file to have the same bitwidth or even type; as opposed to pointers in normal code, that always follows the CPU's constraints). The second one is the datatype of the pointer target, to keep things simple for now, just an UInt32 (but it will be a structure type later).
Finally, RVAToFilePointer is the function that does the mapping from the RVAs stored in the file to absolute file offsets.RVAToFilePointer is a built-in function that gets called whenever a mapping is needed, but I'll expand this to allow for simple functions, that can be declared in HSD, as well.
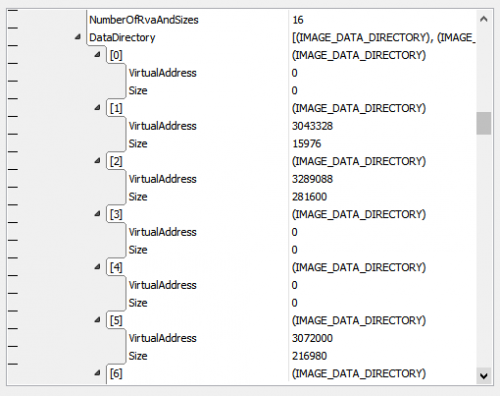
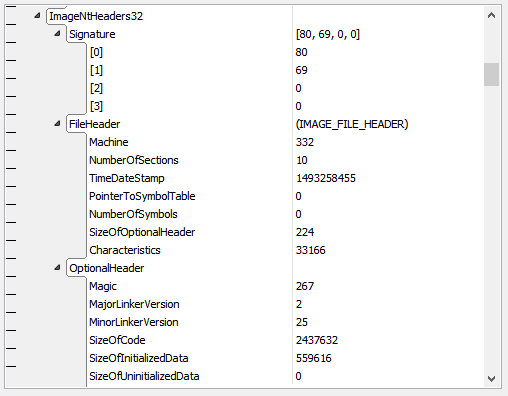
With this new ability, the data directories in the PE file can now be defined as follows, and will be properly found in the structure viewer:
IMAGE_DATA_DIRECTORY = struct { VirtualAddress: PVirtualAddress; Size: UInt32; } -
What is special (besides being able to define dynamic structures and automatically parsing files accordingly), are expressions like this:
DataDirectory: IMAGE_DATA_DIRECTORY[:NumberOfRvaAndSizes];
As you can see in the fourth picture in the post above, the array size of DataDirectory dynamically depends on the field NumberOfRvaAndSize, which was defined earlier in the file, and is displayed accordingly. While with traditional programming language you would need additional code to handle the dynamic nature of the data structure, you can do it declaratively in HSD.
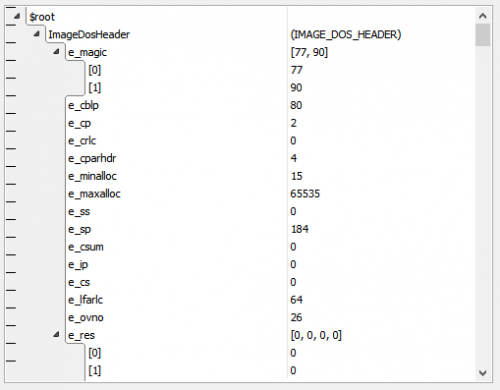
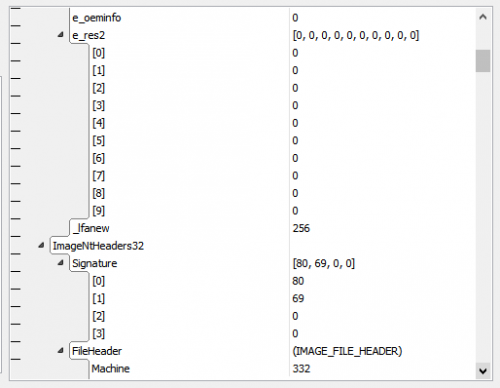
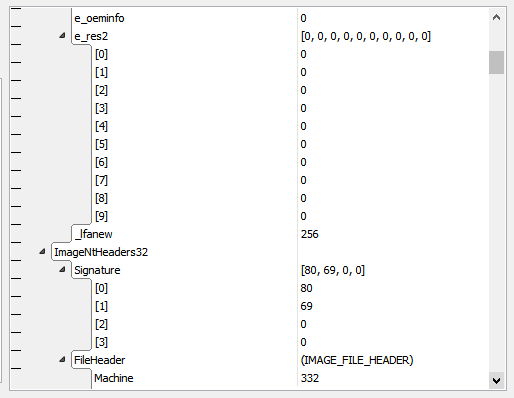
The position of ImageNtHeaders32 is dependent on ImageDosHeader._lfanew, which is a file-dependent offset/pointer and would also require imperative code in traditional languages. In HSD this declaration suffices:
ImageNtHeaders32: IMAGE_NT_HEADERS32 @ :ImageDosHeader._lfanew;
The result can be seen in the second picture in the post above.
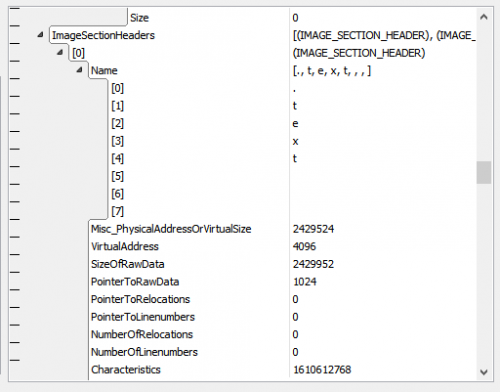
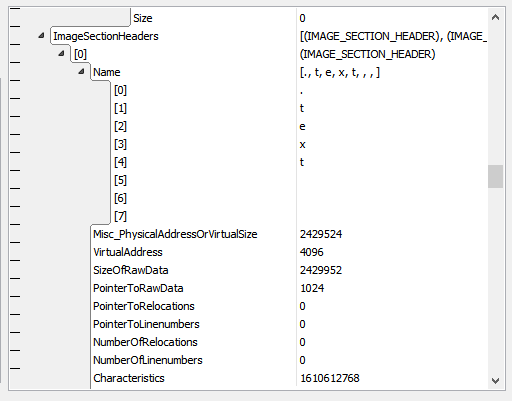
ImageSectionHeaders: IMAGE_SECTION_HEADER[:ImageNtHeaders32.FileHeader.NumberOfSections];
ImageSectionHeaders is defined dynamically, as well. But in such a way that it depends on the two dynamic declarations before (their size and position, that depends on sibling/previous fields). This is because ImageSectionHeaders is the third field in OVERALL_FILE and the preceding fields are of dynamic size, so the position of ImageSectionHeaders adapts accordingly. The size of ImageSectionHeaders is also dynamic, as can be seen when looking at the identifier between [ and ].
-
Currently, I am working again (as mentioned above) on a feature for creating a structure viewer/editor.
PE (portable executable) files are currently the template to determine the necessary functionality (but other file formats like PNG-files and matching features will be added).
Currently, you can define dynamic arrays and structures with dynamic size, where other parts/fields in the file define the size, and pointers are dereferenced automatically.
There is also a feature to map pointers using a function (currently only built-in ones). For PE files this allows mapping RVA (relative virtual addresses) to absolute file offsets.
All of the file structure is given in a declarative language, called HxD structure definition (HSD).
A functional example for parsing PE headers is given below:
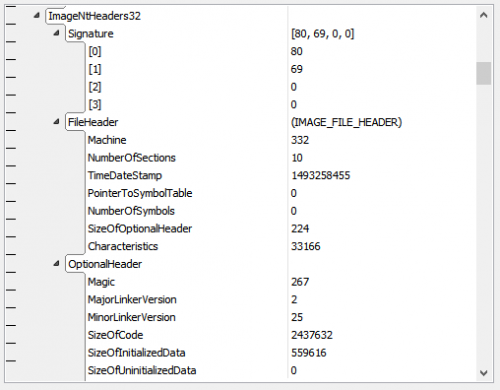
types PVirtualAddress = pointer<UInt32, UInt32> IMAGE_DATA_DIRECTORY = struct { VirtualAddress: UInt32; Size: UInt32; } IMAGE_FILE_HEADER = struct { Machine: UInt16; NumberOfSections: UInt16; TimeDateStamp: UInt32; PointerToSymbolTable: UInt32; NumberOfSymbols: UInt32; SizeOfOptionalHeader: UInt16; Characteristics: UInt16; } IMAGE_OPTIONAL_HEADER32 = struct { Magic: UInt16; MajorLinkerVersion: UInt8; MinorLinkerVersion: UInt8; SizeOfCode: UInt32; SizeOfInitializedData: UInt32; SizeOfUninitializedData: UInt32; AddressOfEntryPoint: UInt32; BaseOfCode: UInt32; BaseOfData: UInt32; ImageBase: UInt32; SectionAlignment: UInt32; FileAlignment: UInt32; MajorOperatingSystemVersion: UInt16; MinorOperatingSystemVersion: UInt16; MajorImageVersion: UInt16; MinorImageVersion: UInt16; MajorSubsystemVersion: UInt16; MinorSubsystemVersion: UInt16; Win32VersionValue: UInt32; SizeOfImage: UInt32; SizeOfHeaders: UInt32; CheckSum: UInt32; Subsystem: UInt16; DllCharacteristics: UInt16; SizeOfStackReserve: UInt32; SizeOfStackCommit: UInt32; SizeOfHeapReserve: UInt32; SizeOfHeapCommit: UInt32; LoaderFlags: UInt32; NumberOfRvaAndSizes: UInt32; DataDirectory: IMAGE_DATA_DIRECTORY[:NumberOfRvaAndSizes]; } IMAGE_NT_HEADERS32 = struct { Signature: UInt8[4]; FileHeader: IMAGE_FILE_HEADER; OptionalHeader: IMAGE_OPTIONAL_HEADER32; } PIMAGE_NT_HEADERS32 = pointer<UInt32, IMAGE_NT_HEADERS32> IMAGE_DOS_HEADER = struct { e_magic: UInt8[2]; e_cblp: UInt16; e_cp: UInt16; e_crlc: UInt16; e_cparhdr: UInt16; e_minalloc: UInt16; e_maxalloc: UInt16; e_ss: UInt16; e_sp: UInt16; e_csum: UInt16; e_ip: UInt16; e_cs: UInt16; e_lfarlc: UInt16; e_ovno: UInt16; e_res: UInt16[4]; e_oemid: UInt16; e_oeminfo: UInt16; e_res2: UInt16[10]; _lfanew: UInt32; } IMAGE_SECTION_HEADER = struct { Name: Char8Ansi[8]; Misc_PhysicalAddressOrVirtualSize: UInt32; VirtualAddress: UInt32; SizeOfRawData: UInt32; PointerToRawData: UInt32; PointerToRelocations: UInt32; PointerToLinenumbers: UInt32; NumberOfRelocations: UInt16; NumberOfLinenumbers: UInt16; Characteristics: UInt32; } IMAGE_IMPORT_DESCRIPTOR = struct { OriginalFirstThunk_ImportLookupTable_RVA: UInt32; TimeDateStamp: UInt32; ForwarderChain: UInt32; Name_RVA: UInt32; FirstThunk_ImportAddressTable_RVA: UInt32; } OVERALL_FILE = struct { ImageDosHeader: IMAGE_DOS_HEADER; ImageNtHeaders32: IMAGE_NT_HEADERS32 @ :ImageDosHeader._lfanew; ImageSectionHeaders: IMAGE_SECTION_HEADER[:ImageNtHeaders32.FileHeader.NumberOfSections]; } instances $root: OVERALL_FILEThe attached pictures show how this is parsed/visualized for my PropEdit.exe (but the solution is generic and works with any 32-bit PE file).
-
 1
1
-
-
It's still very much in development, but I can show some screenshots and show part of the (evolving) syntax, as it is implemented now.
-
I am working on a structure editor right now, so that you can define structure of files, like portable executables, declaratively.
-
@David Champion Thanks for the suggestion. Considering how I would have to keep updating to the most recent Delphi version regularly, and how limited the amount of people is that I would expect to use a hex editor component, it will probably cost me more than I would earn (and require additional support). My assumption is based on the plugin architecture that I published for HxD. While still limited in functionality, it is a first indicator.
But maybe I am missing something?
-
-
Well, I am sure you will understand that it's not really nice to advertise another product in a thread specifically presenting HxD.
I have invested many years into it (since 2002), and it has been Freeware all the time. A little respect for that effort would be appreciated.
-
6
-
-
Thank you everyone for the positive feedback 🙂
On 3/10/2020 at 8:58 AM, Fr0sT.Brutal said:In addition I'd like to have a text viewer (ideally editor) that supports very large files and UTF8.
There is a feature request / progress report regarding UTF-8.
https://forum.mh-nexus.de/viewtopic.php?f=4&t=1004
If you have any comments regarding the design or implementation, please comment there. This is mostly about technical issues of multi-byte encodings and their representation.
-
HxD is a Freeware hex, disk and memory editor, that is fast and can handle files of arbitrary size (up to 8 EiB).
Some of the feature highlights are:
- Disk editor (automatically unmounts drives as necessary when saving changes)
-
Memory editor (full support for 64 and 32-bit)
- Data folding, for easier overview and hiding inaccessible regions
-
Data inspector
- Converts current data into many types, for editing and viewing
- Open source plugin-framework to extend with new, custom type converters
- Search and replace with support for various data types
- Importing and exporting of Intel Hex, Motorola S-Records
- Exporting to Pascal, C, Java, C#, VB.NET, PureBasic, but also HTML, RTF, and TeX
- Checksum and hash generation and validation
- File compare
- Tools to split, join and shredder files
Currently, available in version 2.4 and 17 languages: HxD download.
P.S.: If you like it, please star the code on GitHub or give it a (good 😉) rating on download sites.
-
6
-
 3
3
-
On 7/2/2019 at 10:51 PM, Bill Meyer said:There may well be other strategies which might be applied to avoid the issue with search path, but I consider it poor practice not to name all your own units as members of the project.
When using components or libraries, I think it is poor practice to include them in your projects, since they are shared files. They should be compiled independently to ensure you use the same version and state everywhere. All major Delphi components work this way, and you don't include the RTL or VCL units in your projects, either.
When placing components on the form, this should work seamlessly, and not require editing project specific library paths (or the IDE should do it automatically).
The IDE is just buggy regarding code completion and parsing, to more or less severe degrees depending on the version. This scenario is a very standard one, and should work.
-
I finally wrote a class to iterate over a range of parameters for hash functions/tables chained one after another.
First I thought about using some optimization algorithm, like gradient descent, but it proved hard to write a reasonable error function which has gradients that are smooth and wide enough for optimization to work well. So I simply iterated over a reasonable range of the parameters until a satisfyingly small size was found.
I could reduce the size of 1088 KiB (1 Byte for each of the 1114112 code points), to 16 KiB while keeping random access (three chained hash table lookups and three hash functions to compute the index/key for each hash table), which I think is good enough.
-
I replied there. Couldn't find my old account information, so I had to make a new one.
As can be seen there this is not related to MMX, and I did not make a wrong bug report @timfrost.
-
1
-
-
I would not try to interpret strings encoded in a special way (such as using # and a number, or string lists which generate a list of lines which begin and end with ' and have a special escaping for '). You would expect the text search to work with the verbatim text file, and only consider things such as text encoding (UTF-8, Windows-1252) that applies to every text file, but otherwise nothing smart that does syntax interpretation.
If such a mode would be introduced, I think it should be an explicit option, then people will also be less surprised by behavioral changes (only if that option is checked).
-
Thanks for maintaining GExperts!
In the latest release (but also in older releases), some action seems to take over the shortcut Ctrl+Alt+C which is usually reserved for showing the CPU window in debug mode.
I only found the editor expert "Copy Raw String" with this shortcut, and disabled it, but the shortcut is still "caught" by some GExperts code. If I disable GExperts, everything is fine again.
-
Reading the thread it seems to confirm my theory in the other thread you posted @dummzeuch, that the issue is related to reference counting. Some code is probably treating WideStrings (which are COM strings) as UnicodeStrings (which are reference counted) or somehow misinterpreting/casting data types along the way.
@Sue King: It would be helpful if you could provide links (or simply attach) both versions of dxgettext, the old one that worked, and the new one that doesn't. If there is a minimal demo, which works with nexus db trial DCUs, that would be even better.
-
2009 was the first to introduce Unicode and UnicodeString, so it's very likely UTF8ToUnicodeString did not exist before that.
But you could use IFDEFs to define UnicodeString as WideString for pre-Unicode Delphi versions, and make a stub UTF8ToUnicodeString that calls UTF8ToWideString.
That's how I used to do it, and it worked well. WideString will still not be reference counted of course.
A reason for the original issue could be reference-counting. I remember that Andreas Hausladen implemented reference counting for WideStrings, with a hack. I am not sure anymore how it was implemented, and how deep the hack went (a quick search didn't turn up anything). But if people have this patch installed, it may have unintended consequences, which might have caused the issue.
-
Thanks a lot for your input, Mahdi.
I wanted to post working code once it's finished and polished, but that will take a while, as I have to solve other parts of the software first.
Your solution is somewhat similar to what I tried, however this is limited to values <= UInt16 (as you noted), whereas Unicode code points range from 0 to $10FFFF. The other issue is that while TUnicodeCategory was in the question, I wanted to implement a general solution, where ranges aren't necessarily as regular (lookup tables for other properties of codepoints where they don't build such nice ranges) or working with the specifically chosen "hash keys" that will not work when your ranges are not as good.
Ideally I was looking for an algorithm that automatically searches for the proper hash functions that would yield a reasonably small hash table. Or at least a principle algorithm for it.
I'll have a look at your solution again, though, if I need to optimize my approach further.
-
After more analysis I found out the tables implement a 3 level hashmap, or actually three hashmaps that are used consecutively to implement the mapping from codepoints to categories.
I have been able to reverse engineer part of the hash functions, but besides the first table, I don't get identical results for the table values or table sizes.
The overall mapping from codepoints to categories works however.
The second table CatIndexSecondary increases its values in steps of 16 every time a bucket with a collision is found. If there is a bucket that has a single value (i.e., no collisions), and that single value appears again in another bucket, they both get assigned the same index. Sometimes though it gets strange and suddenly values get large, apparently to provide more room for collision avoidance, but it's not obvious how they are computed.
It is also strange that a value between 0..15 is added to the result of a mapping with CatIndexSecondary. It would cause collisions if the values in CatIndexSecondary are not carefully chosen to avoid that. The increment in steps of 16 would ensure this happens, but not all values are computed in such a straight forward way. Maybe the increments in steps of 16 are a first attempt, then a check for collisions occurs, and remaining gaps in the index numbers are filled to reduce the size of the hashmap incrementally.
I know this remains vague, but it's at least a quick progress update.
-
Thanks. There is definitely a structure and ranges that are assigned the same value. But there is no special documentation in the Unicode standard that would go beyond what you can directly deduce from the mapping available in Delphi. I actually started with the standard, then looked for efficient encodings. The standard vaguely suggests using a data structure like a trie.
The Unicode documentation itself only lists every character and gives it a matching category.
The Delphi implementation apparently uses some kind of Hashmap. But I haven't been able to figure out the "inverse function" yet, to create the table.
Edit: I have looked into writing my own hashing function, assuming the division of the original key into three parts (one 13 bit key, and two 4 bit keys) as the original RTL code does. I could reproduce the values after a while, eventhough it seems the RTL wastes a bit of value range. I will update this post when I found out the final solution.


HxD hex, disk and memory editor
in I made this
Posted · Edited by mael
HxD 2.5 was released with many feature enhancements and bug fixes.
Here are the change log and the download.
GregC/DigicoolThings published a disassembler plugin on GitHub for MC6800, MC6809, 6502 and related CPUs.
The updated plugin framework can be found, here, as usual:
https://github.com/maelh/hxd-plugin-framework
If you like it, please star / fork it, so it becomes more well known.
Donations are welcome if you want to say thanks.