

Arnaud Bouchez
-
Content Count
316 -
Joined
-
Last visited
-
Days Won
22
Posts posted by Arnaud Bouchez
-
-
3 hours ago, David Heffernan said:@Arnaud Bouchez How do you handle a line longer than your buffer?
I would just cut a line bigger than this size - which is very unlikely with a 2MB buffer.
Or just don't cut anything, just read the buffer and use a proper simple state machine to decode the content, without allocating any string. -
@Vandrovnik I guess you didn't understand what I wrote.
I proposed to read the files in a buffer (typically 2MB-32MB), chunk by chunk, searching for the line feeds in it.
It will work, very efficiently, for any size of input files - even TB.Last trick: under Windows, check the FILE_FLAG_SEQUENTIAL_SCAN option when you open such a huge file.
It bypasses the OS cache, so make it more efficient in your case.See the corresponding function in SynCommons.pas :
/// overloaded function optimized for one pass file reading // - will use e.g. the FILE_FLAG_SEQUENTIAL_SCAN flag under Windows, as stated // by http://blogs.msdn.com/b/oldnewthing/archive/2012/01/20/10258690.aspx // - under XP, we observed ERROR_NO_SYSTEM_RESOURCES problems with FileRead() // bigger than 32MB // - under POSIX, calls plain FileOpen(FileName,fmOpenRead or fmShareDenyNone) // - is used e.g. by StringFromFile() and TSynMemoryStreamMapped.Create() function FileOpenSequentialRead(const FileName: string): Integer; begin {$ifdef MSWINDOWS} result := CreateFile(pointer(FileName),GENERIC_READ, FILE_SHARE_READ or FILE_SHARE_WRITE,nil, // same as fmShareDenyNone OPEN_EXISTING,FILE_FLAG_SEQUENTIAL_SCAN,0); {$else} result := FileOpen(FileName,fmOpenRead or fmShareDenyNone); {$endif MSWINDOWS} end;
-
 1
1
-
-
For decoding such log lines, I would not bother about UTF-8 decoding, just about line feeds decoding, during file reading.
Just read your data into a buffer (bigger than you expect, e.g. of 2MB, not 32KB), search for #13#10 or #10, then decode the UTF-8 or Ansi text in-between - only if really needed.
If you don't find a line feed before the end of the buffer, copy the bytes remaining from the last line at the beginning of the buffer, then fill it from disk.
Last but not least, to efficiently process huge log files which are UTF-8 or Ansi encoded, I wouldn't make any conversion to string (UnicodeString), but use raw PAnsiChar or PByteArray pointer, with no memory allocation.
We have plenty of low-level search / decoding functions working directly into memory buffers (using pointers) in our Open Source libraries https://github.com/synopse/mORMot/blob/master/SynCommons.pas
-
When I switched to Ubuntu for main OS, I put Ubuntu Mono in my Lazarus IDE and I like the result very much:
-
1
-
-
They could be changed, of course.
To be honnest, if you expect to defeat hackers you most probably will loose your time - especially if you don't know how to convert i386 asm to x64.
Even the asm trick used in this code could be disabled - see https://www.gta.ufrj.br/ensino/CPE758/artigos-basicos/carpenter07.pdf and http://www.trapkit.de/tools/scoopyng/SecureVMX.txt just after a quick Google Search.
And BTW Wine is not a virtual machine, I don't understand why it is part of this detection.
-
1
-
-
Why not get the BIOS description string?
The kind of Virtual machine is clearly available there.
Just read in the registry: HKEY_LOCAL_MACHINE\Hardware\Description\System\BIOS
This is how we do in our Open Source mORMot framework:
with TRegistry.Create do try RootKey := HKEY_LOCAL_MACHINE; if OpenKeyReadOnly('\Hardware\Description\System\CentralProcessor\0') then begin cpu := ReadString('ProcessorNameString'); if cpu='' then cpu := ReadString('Identifier'); end; if OpenKeyReadOnly('\Hardware\Description\System\BIOS') then begin manuf := SysUtils.Trim(ReadString('SystemManufacturer')); if manuf<>'' then manuf := manuf+' '; prod := SysUtils.Trim(ReadString('SystemProductName')); prodver := SysUtils.Trim(ReadString('SystemVersion')); if prodver='' then prodver := SysUtils.Trim(ReadString('BIOSVersion')); if OpenKeyReadOnly('\Hardware\Description\System') then begin if prod='' then prod := SysUtils.Trim(ReadString('SystemBiosVersion')); if prodver='' then begin prodver := SysUtils.Trim(ReadString('VideoBiosVersion')); i := Pos(#13,prodver); if i>0 then // e.g. multilines 'Oracle VM VirtualBox Version 5.2.33' SetLength(prodver,i-1); end; end; if prodver<>'' then FormatUTF8('%% %',[manuf,prod,prodver],BiosInfoText) else FormatUTF8('%%',[manuf,prod],BiosInfoText); end; finally Free; end;
-
Isn't it also used for some kind of Vodka ?
- ok I am out (like the variables)
-
 2
2
-
-
10 hours ago, Lars Fosdal said:https://www.copytrans.net/copytransheic/ installs a driver for Windows Imaging Component that allows conversion with WIC and is, as far as I can tell, free.
Brillant!
Do you know if it is compatible with the built-in https://blogs.windows.com/windowsexperience/2018/03/16/announcing-windows-10-insider-preview-build-17123-for-fast/#hL2gI3IBkfsGuK6d.97 ?
Do you know the WIC identifiers involved? -
On 10/9/2019 at 4:38 PM, Darian Miller said:Any plans to support more platforms in Delphi? I don't use FPC at all.
We don't use Delphi for other platforms.... but FPC...
There is no plan yet, due to how incompatible cross-platform was in Delphi. And even with ARC disabled, I am not sure it would be worth it.There is a very small test framework in our Cross-Platform client units.
See https://github.com/synopse/mORMot/blob/master/CrossPlatform/SynCrossPlatformTests.pas
It is very lightweight, and should work on all platforms...
-
 1
1
-
-
For information, our Open Source https://github.com/synopse/mORMot/blob/master/SynCrtSock.pas supports SChannel as TLS layer since some time, for its raw socket layer.
Of course, there is the additional WinInet/WinHTTP API for HTTP requests, which supports proper Proxy detection.Its SChannel implementation is more concise that your propose, and it works from Delphi 6 and up, and also for FPC.
See https://github.com/synopse/mORMot/blob/5777f00d17fcbe0378522ceddceb0abece1dd0e3/SynWinSock.pas#L847
-
1
-
-
We use our Open Source https://github.com/synopse/mORMot/blob/master/SynTests.pas unit.
It is cross-platform and cross-compiler (FPC and Delphi).
But it is mostly about server-side process and Win32/Win64 for Delphi.
It is cross-platform (Win, BSD, Linux, i386/x86-64/arm32/aarch64) for FPC.-
1
-
-
It would make sense only if your data consist in text files, and you want to keep versioning of the information.
A regular SQL database would replace the old data, so you would need to log the old values in a dedicated table.You can use the git command-line for all features you need.
Just call it with the proper argument from your Delphi application.But I would rather take a look at https://www.fossil-scm.org/home/doc/trunk/www/index.wiki
It is an efficient Distributed Version Control Management system, very similar to git, but with a big difference:"Self-Contained - Fossil is a single self-contained stand-alone executable. To install, simply download a precompiled binary for Linux, Mac, or Windows and put it on your $PATH. Easy-to-compile source code is also available"
So you could be able to much easier integrate it to your own software.
It has some other nice features - like an integrated Web Server - which could be easy for you.Here also, you would need to call the fossil command line from your Delphi application.
-
1
-
-
On 9/8/2019 at 9:11 AM, aehimself said:- Some database engines can not search in BLOB fields. Now it might not be an issue in the beginning but it makes investigating data corruption / debugging processing issues a living nightmare
- Downloading blob fields are slow, no matter what. Especially over the network. In our production databases I can select hundreds of thousands of rows with 150+ columns but only a fraction of that 2 fields: an ID and a BLOB storing an XML
- Database engines are robust, they were built for having columns. While it can be hard / intimidating to see the relations at first time, they have no issues handling a larger number of columns
- Unless the DB engine has built-in JSON support, you'll not be able to query and compare a specific value on database side, you'll always have to download and compare from code, increasing memory, network and CPU usage of your program. Considering a well-fed metal (our slang for a server with enough resource + overhead) running the database, this will always be significantly slower than letting the DB engine to take care of these
The only reasonable case when storing a JSON / XML in a database I can see is if you receive that from an external source (like a REST server or a 3rd party sending your software some information) and you want to keep those chunks for auditing purposes. Sooner or later you'll face one of the issues I mentioned, though 🙂
We did the same about 8 years ago (only with XMLs) and now we are looking into opportunities to undo it...
@aehimself I do not have the same negative experience in practice.
In fact, your last point gives light to the previous one: "DB engine has built-in JSON support" is needed.
I stored JSON in DB with great success for several projects.
Especially in a DDD project, we use our ORM to store the "Aggregate" object, with all its associated data objects and arrays serialized as JSON, and some indexed fields for quick query.
If the architecture starts from the DB, which is so 80s, using JSON doesn't make sense. But if the architecture starts from the code, which is what is recommended in this century with new features like NoSQL and ORM running on high-end hardware, then you may have to enhance your design choices. Normalizing data and starting from the DB is perfectly fine, for instance if you make RAD or have a well-known data layout (e.g. accounting), but for a more exploring project, it will become more difficult to maintain and evolve.
"- Some database engines can not search in BLOB fields. Now it might not be an issue in the beginning but it makes investigating data corruption / debugging processing issues a living nightmare"
-> this is why I propose to duplicate the searched values in its own indexed fields, and only search the JSON once it is refined; and do not use BLOB binary fields, but CTEXT fields.
"Downloading blob fields are slow, no matter what"
-> it is true if you download it, but if the JSON process is done on the server itself, using JSON functions as offered e.g. by PostgreSQL or SQLite3, it is efficient (once you pre-query your rows using some dedicated indexed fields)"they have no issues handling a larger number of columns"
-> main idea of using JSON is not to have a fixed set of columns, but being able to store anything, with no pre-known schema, and with several level of nested objects or arrays. -
MongoDB benefit is to be installed in its server(s), with proper replication.
Using it stand-alone is pointless.Use SQlite3 as embedded database.
It supports JSON https://www.sqlite.org/json1.html efficiently.In practice, on some production project we used:
- SQLite3 for almost everything (up to 1TB databases) - and we usually create several databases, e.g. per-user DB
- MongoDB for storing huge content (more than 1TB databases) with replication: typically used as an archive service of "cold" data, which can be queried efficiently if you defined the proper indexes
To let all this work from Delphi, we use our OpenSource http://mormot.net ORM, which is able to run efficiently on both storages, with the exact same code.
The WHERE SQL query clauses are even translated on the fly to MongoDB pipelines by the ORM.
One main trick is to put raw data as JSON in the RawJSON or TDocVariant ORM fields, then duplicate the fields to be queried as stand-alone ORM properties, with a proper index. Then you can query it very efficiently.
-
On 9/22/2019 at 11:22 AM, Dalija Prasnikar said:Unless someone designed framework poorly.
There is also possibility that framework is only for Windows and cannot be used as cross-platform solution. Still, people might use FMX only on Windows, so naming framework VCL would be poor choice in such case.
You are right, SynCrypto is fine with FMX running on Windows - and it uses RawByteString or TBytes as required since Delphi 2009. But it is not a OS compatibility problem - it is a compiler issue.
To be fair, it's Delphi cross-platform compiler/RTL which is designed poorly, especially all the backward compatibility breaks they made about strings and heap.
Their recent step back is a clear hint of their bad design choices.There is no problem to use SynCrypto on Windows, Linux, BSD, Darwin, for Intel/AMD or ARM 32-bit or 64-bit CPU, if you use FPC.
But we didn't lose time with targets breaking too much the existing code base. I am happy I didn't spend weeks making mORMot ARC-compatible - which is now deprecated! - and focused instead on FPC compatibility and tuning. Which was very rewarding.-
2
-
-
For a regular SQL DB, I would use a BLOB SUB_TYPE TEXT field, to store the JSON content.
Then duplicate some JSON fields in a dedicated stand-alone SQL field (e.g. a "id" or "name" JSON field into regular table.id or table.name fields in addition to the table.json main field), for easy query - with an index if speed is mandatory.
So, start with JSON only (and a key field), then maybe add some dedicated SQL fields for easier query, if necessary.
side note: I would rather use SQLite3 or PostgreSQL for efficiently storing JSON content: both have efficient built-in support. Or a "JSON native" database like MongoDB.
-
3
-
1
-
-
I don't agree - don't add new private methods. It is not SOLID. Try to keep the class definition small and readable.
Rather add a hidden object or class in your implementation section.
-
1
-
-
Our Open-Source https://github.com/synopse/mORMot/blob/master/SynCrypto.pas has almost all that you require.
About performance, it is the only one in the Delphi area using AES-NI and optimized SSE3/SSE4.2 assembly - as far as I know. So it should blow alternatives.
It is cross-compiler (Delphi and FPC) and cross-platform (Windows, Linux, BSD... thanks to FPC).
For elliptical curves, see its sibbling https://github.com/synopse/mORMot/blob/master/SynEcc.pas
It supports only secp256r1 but it is feature complete (e.g. simple CA management) and fast (1 ms to create a key pair, 0.4 ms to sign or verify on x86-64) - also cross-platform and cross-compiler.
See the documentation at https://synopse.info/files/html/Synopse mORMot Framework SAD 1.18.html#TITL_187
Both are highly maintained, and used on production since years.
They don't require any external dll (like OpenSSL) which tends to be a maintenance nightmare on Windows.-
2
-
1
-
-
Yes, @Bill Meyer is right: do not put the nested functions part of the main class. It would break SOLID principles for sure - at least the single responsibility. Always favor composition in OOP.
About refactoring and breaking huge functions, you could take a look at those slides:
Following these proposals, for code refactoring, I would move the code into dedicated records with methods (or classes).
-
1
-
-
17 hours ago, Alexander Elagin said:I'd rather replace a direct client-server solution with a 3-tier one, thus totally isolating the database from network access.
Switch to a n-Tier architecure is the way to go.
Keep the database locally on your server computer (or network), then use regular REST/JSON over secure HTTPS for the communication with clients.
HTTPS will be much easier to secure and scale than forcing encryption with the database driver. Certificate management is a difficult think to do - I have seen so many solutions running fine... until a certificate becomes obsolete. 😉
We usually use a nginx server as reverse proxy, with https://letsencrypt.org/ certificate management.-
1
-
-
A quick and simple rule would be to define only mandatory variables as shared for the nested procedures, i.e. above them.
That is, try to keep all variables of the main block in the lower part of the code, just before the main block.
Just as you did.From my experiment, nested functions are fine if there is only 1 (or 2) of them.
Once I reach the number of 2/3 nested functions, I usually define a private record type, with proper methods. It is kept private in the implementation section of the unit.
The trick of using a record with methods, and not a class, allows to allocate it on the stack in the main method, with no try..finally Free block.It is much cleaner (more SOLID), and also much more extendable.
The main benefit is that it is re-usable: you could reuse some code, in another function.
Last but not least, you have the possibility to add a unitary test method, and browse easier the code in your IDE.-
1
-
-
with SomeUnitName do doesn't compile on my Delphi 10.3 (nor FPC).
Compiler complains with[dcc64 Error] Test.dpr(200): E2029 '.' expected but 'DO' found
-
 1
1
-
-
-
What is sure with "with" discussion is that it is a trolling subject in the Delphi community since decade(s).
For instance, the topic is about "with" in general, and that @Yaron stated that the IDE debugger has troubles with it.
TRect came as a true problem about "with" - I do agree with Stefan. But problem came from Embarcadero, not taking into account existing code base. Just like ARC, or the AnsiStrings...Most dev people outside this forum would argue, paraphrasing @Dalija Prasnikar, that 'Delphi is a relic of another time and another coding practices: for instance, there is no GC !'.
Php adepts would argue that writing $this->foo is much cleaner/safer than what Delphi (and other languages) do about properties.
I like "with" - when properly used for two-liners code - as I wrote. It is a clean way of writing code, "making it easier to read" as wrote Yaron.
Similarly, I like "object" more than "record with methods", since it allows easy inheritance - when using high-performance code with pointers and pre-allocated memory buffers/arrays. Of course, with only static methods.
This was just my 2 cents, to introduce another POV into the discussion. Nothing is totally black nor white.-
2
-

Reading large UTF8 encoded file in chunks
in RTL and Delphi Object Pascal
Posted
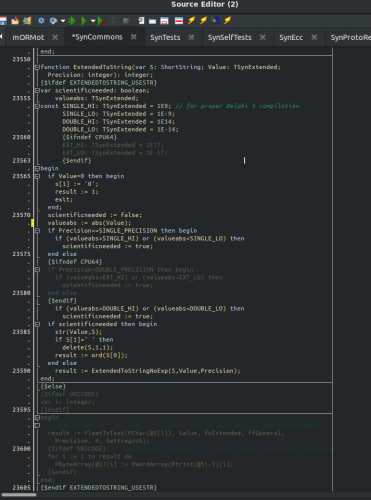
We use similar techniques in our SynCommons.pas unit. See for instance lines 17380 and following:
In fact, the state machine I talked about was just about line feeds, not UTF-8. My guess was that UTF-8 decoding could be avoided during the process.
If the lines are not truncated, then UTF-8 and Ansi bytes will be valid sequences.
Since when processing logs, lines should be taken into account, a first scan would be to decode line feeds, then process the line bytes directly, with no string/UnicodeString conversion at all.
For fast searching within the UTF-8/Ansi memory buffer, we have some enhanced techniques e.g. the SBNDM2 algorithm: see TMatch.PrepareContains in our SynTable.pas unit. It is much faster than Pos() or BoyerMore for small patterns, with branchless case-insensitivity. It reaches several GB/s of searching speed inside memory buffers.
There is even a very fast expression search engine (e.g. search for '404 & mydomain.com') in TExprParserMatch. More convenient than a RegEx to me - for a fast RegEx engine, check https://github.com/BeRo1985/flre/
Any memory allocation would reduce a lot the process performance.